Bra podcast
Sveriges mest populära poddar

2025年这个春节,DeepSeek一举改写了全球AGI大叙事。在万般热闹之际,我们特别想沉下来做一些基础科普工作,一起来研读这几篇关键的技术报道。
今天这集节目,我邀请加州大学伯克利分校人工智能实验室在读博士生潘家怡,来做技术解读。他的研究方向是语言模型的后训练。
这期播客中,家怡将带着大家一起来读,春节前DeepSeek发布的关键技术报告,他在报告中发布了两个模型DeepSeek-R1-Zero和DeepSeek-R1;并对照讲解Kimi发布的K1.5技术报告,以及OpenAI更早之前发布的o1的技术博客,当然也会聊到它春节紧急发布的o3-mini。这几个模型聚焦的都是大模型最新技术范式,RL强化学习。
希望我们的节目能帮更多人一起读懂这几篇论文,感受算法之美,并且准确理解目前的技术拐点。
(以下每篇技术报告都附了链接,欢迎大家打开paper收听✌️)
期待2025,我们和AI共同进步!


【嘉宾小记】
加州大学伯克利分校人工智能实验室在读博士生,上海交通大学本科毕业。他的研究方向主要集中在语言模型的后训练领域,通过强化学习等方法提升AI在智能体行为决策与推理方面的能力。这是他做的有关R1-Zero小规模复现工作:github.com
我们的播客节目在腾讯新闻首发,大家可以前往关注哦,这样可以第一时间获取节目信息和更多新闻资讯:)

03:46 讲解开始前,先提问几个小问题
16:06 OpenAI o1技术报告《Learning to reason with LLMs》讲解
报告链接:openai.com
中文标题翻译:《让大语言模型学会推理》
OpenAI在报告中有几个重点:
- Reinforcement Learning — 强化学习
- It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. (它学会识别并纠正自己的错误,学会将复杂的步骤分解为更简单的步骤,学会在当前方法行不通时尝试不同的解决途径。)这些是模型自己学的,不是人教的。
- 我们还在技术早期,他们认为这个技术可拓展,后续性能会很快攀升。
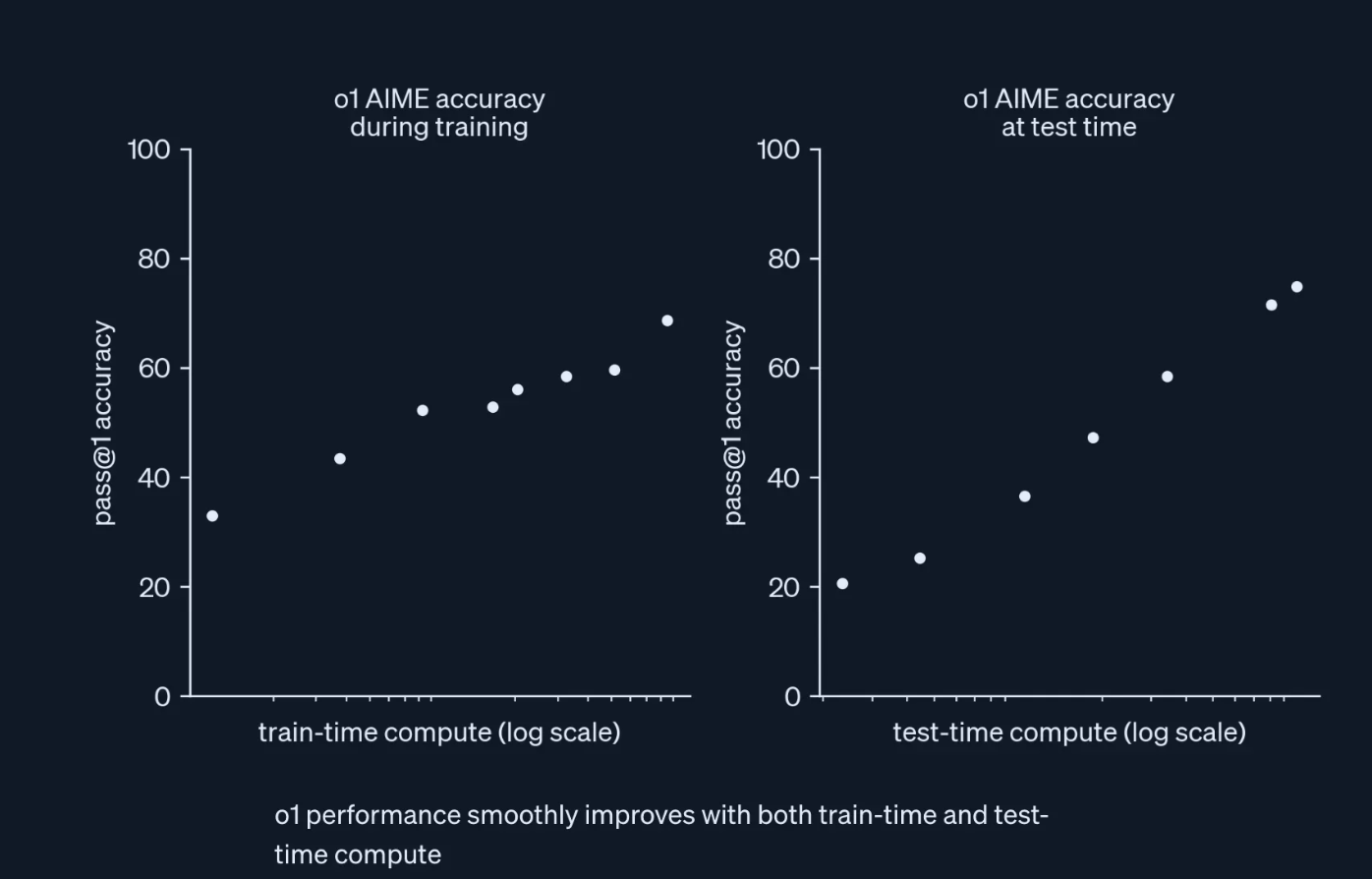
33:03 DeepSeek-R1-Zero and DeepSeek-R1技术报告《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》讲解
报告链接:github.com
中文标题翻译:《DeepSeek-R1:通过强化学习激励大语言模型的推理能力》
35:24 摘要(Abstract)
37:39 导论(Introduction)
44:35 发布的两个模型中,R1-Zero更重要还是R1更重要?
47:14 研究方法(Approach)
48:13 GRPO(Group Relative Policy Optimization,一种与强化学习相关的优化算法)
57:22 奖励建模(Reward Modeling)
01:05:01 训练模版(Training Template)
01:06:43 R1-Zero的性能、自我进化过程和顿悟时刻(Performance, Self-evolution Process and Aha Moment)
值得注意的是,“Aha Moment”(顿悟时刻)是本篇论文的高潮:
报告称,在训练DeepSeek-R1-Zero的过程中,观察到一个特别引人入胜的现象,即“顿悟时刻”。这一时刻出现在模型的中间版本中。在这个阶段,DeepSeek-R1-Zero通过重新评估其最初的方法,学会了为一个问题分配更多的思考时间。这种行为不仅是模型推理能力不断增长的有力证明,也是强化学习可能带来意想不到且复杂结果的一个迷人例证。
这一时刻不仅是模型的“顿悟时刻”,也是观察其行为的研究人员的“顿悟时刻”。它凸显了强化学习的力量与美感:我们并没有明确地教导模型如何解决问题,而是仅仅为其提供了正确的激励,它便自主地发展出高级的问题解决策略。这种“顿悟时刻”有力地提醒我们,强化学习有潜力在人工智能系统中解锁新的智能水平,为未来更具自主性和适应性的模型铺平了道路。
01:14:52 模型能涌现意识吗?
01:16:18 DeepSeek-R1:冷启动强化学习( Reinforcement Learning with Cold Start)
01:24:48 为什么同时发布两个模型?取名“Zero”的渊源故事?
01:28:51 蒸馏:赋予小模型推理能力(Distillation: Empower Small Models with Reasoning Capability)
01:35:27 失败的尝试:过程奖励模型(PRM)与蒙特卡罗树搜索(MCTS)
01:42:33 DeepSeek-R1技术报告是一片优美精妙的算法论文,有很多“发现”,这是它成为爆款报告的原因
01:43:50 对DeepSeek-R1训练成本的估算:
往高里估,一万步GRPO更新, 每步就算1000的batch size(试一千次),一次算一万个token;模型更新用的
- $2.2 / 1M tokens,
- 总共是100B tokens — 0.22M
- 算上效率损失,模型训练也有一定开销,说破天也就1M;如果优化的话很有可能只有10万美金左右的成本
- 相比之下,预训练用了600万美金,相当便宜
01:49:05 KIMI K1.5技术报告《KIMI K1.5:
SCALING REINFORCEMENT LEARNING WITH LLMS》讲解
中文标题翻译:《KIMI K1.5:利用大语言模型扩展强化学习》
报告链接:arxiv.org
该报告公开了许多技术技巧细节,对于想要复现的人,两篇paper一起使用更佳。如,数据构造、长度惩罚、数学奖励建模、思维链奖励模型、异步测试、Long2short、消融实验等。
02:20:07 DeepSeek论文的结尾谈未来往哪里发展?
02:24:35 以上是三篇报告所有内容,接下来是提问时间,我们继续强化学习一下!
“数据标注”在几篇论文中藏得都比较深,小道消息OpenAI一直以100-200美元/小时找博士生标数据
“DeepSeek的论文隐藏了技术细节,但把算法的精妙之处和美展现给你,让你感受技术之美,给你震撼。”
它解密了后训练范式革命可以何处去,让你发现原来算法这么简单!
再一次验证——“最优美的算法永远是最干净的。”

关于强化学习往期节目:
AGI范式大转移:和广密预言草莓、OpenAI o1和self-play RL|全球大模型季报4
和OpenAI前研究员吴翼解读o1:吹响了开挖第二座金矿的号角
王小川返场谈o1与强化学习:摸到了一条从快思考走向慢思考的路
开源一场关于DeepSeek的高质量闭门会:
一场关于DeepSeek的高质量闭门会:“比技术更重要的是愿景”
【更多信息】
联络我们:微博@张小珺-Benita,小红书@张小珺
更多信息欢迎关注公众号:张小珺

Kategorier
Förekommer på
00:00
-00:00