Bra podcast
Sveriges mest populära poddar
“A Problem to Solve Before Building a Deception Detector” by Eleni Angelou, lewis smith
24 min •
8 februari 2025
TL;DR: If you are thinking of using interpretability to help with strategic deception, then there's likely a problem you need to solve first: how are intentional descriptions (like deception) related to algorithmic ones (like understanding the mechanisms models use)? We discuss this problem and try to outline some constructive directions.
1. Introduction
A commonly discussed AI risk scenario is strategic deception: systems that execute sophisticated planning against their creators to achieve undesired ends. In particular, this is insidious because a system that is capable of strategic planning and also situationally aware might be able to systematically behave differently when under observation, and thus evaluation methods that are purely behavioral could become unreliable. One widely hypothesized potential solution to this is to use interpretability, understanding the internals of the model, to detect such strategic deception. We aim to examine this program and a series of problems that appear [...]
---
Outline:
(00:28) 1. Introduction
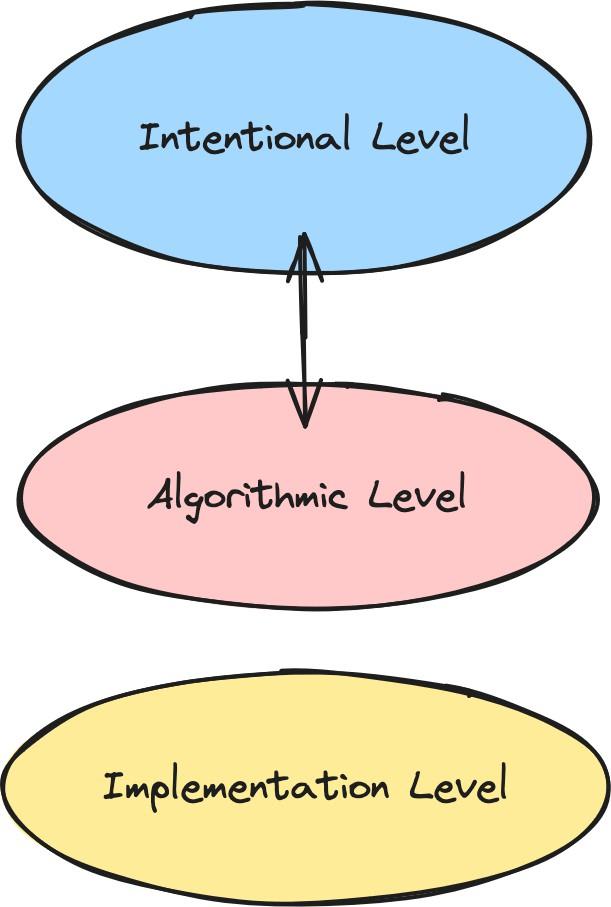
(02:38) 2. The intentional and the algorithmic
(06:21) 3. What is the problem?
(11:56) 4. What deception, exactly?
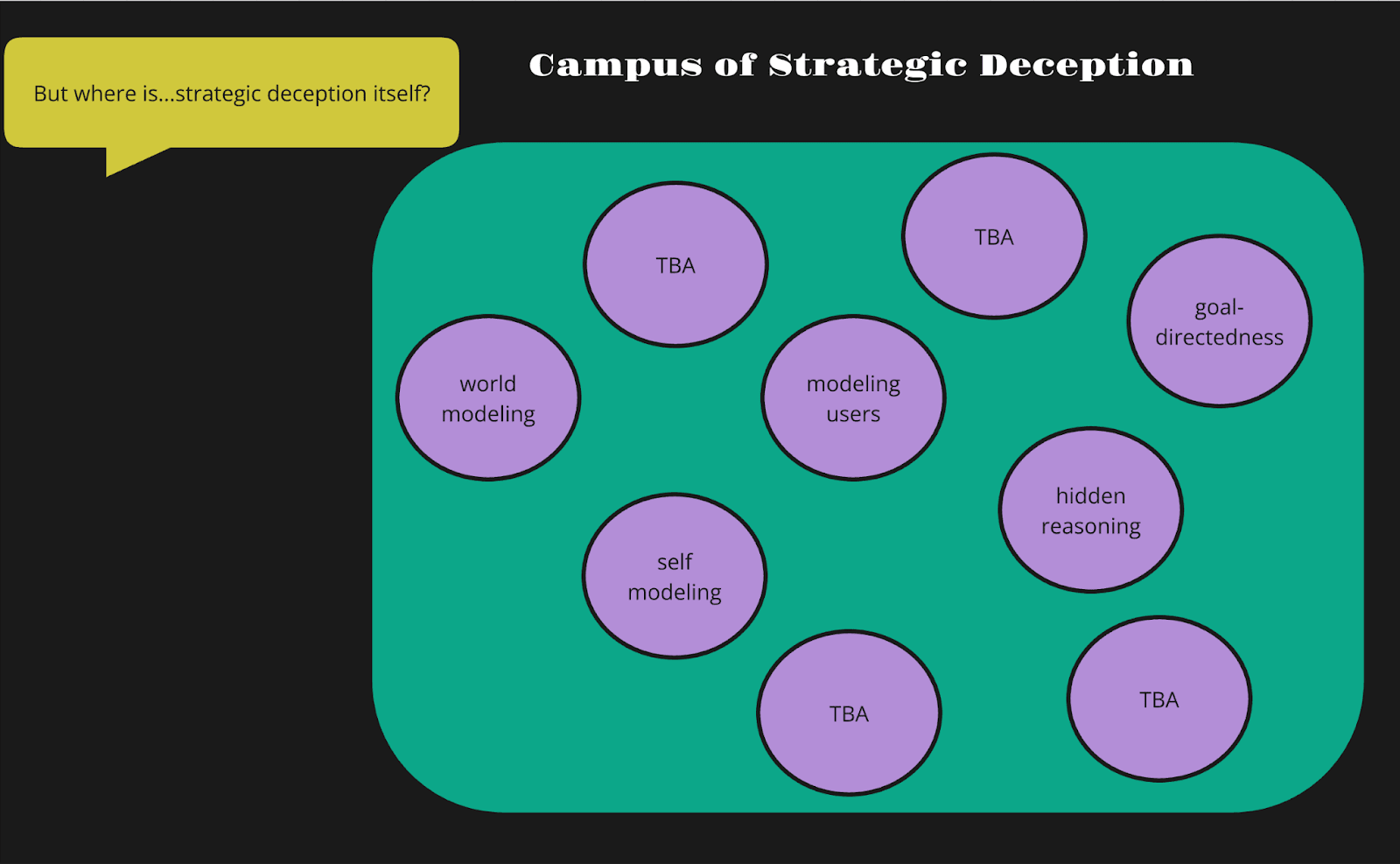
(14:10) 5. Decomposing strategic deception
(14:53) 5.1. Developing world models
(16:22) 5.2. Modeling the self
(17:29) 5.3. Modeling user states
(18:28) 5.4. Long-term goal directedness
(19:32) 5.5. Hidden reasoning
(21:09) 6. Conclusions and Suggestions
(23:02) Acknowledgments
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
February 7th, 2025
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00