Bra podcast
Sveriges mest populära poddar
(Audio version here (read by the author), or search for "Joe Carlsmith Audio" on your podcast app.
This is the fourth essay in a series that I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.)
1. Introduction and summary
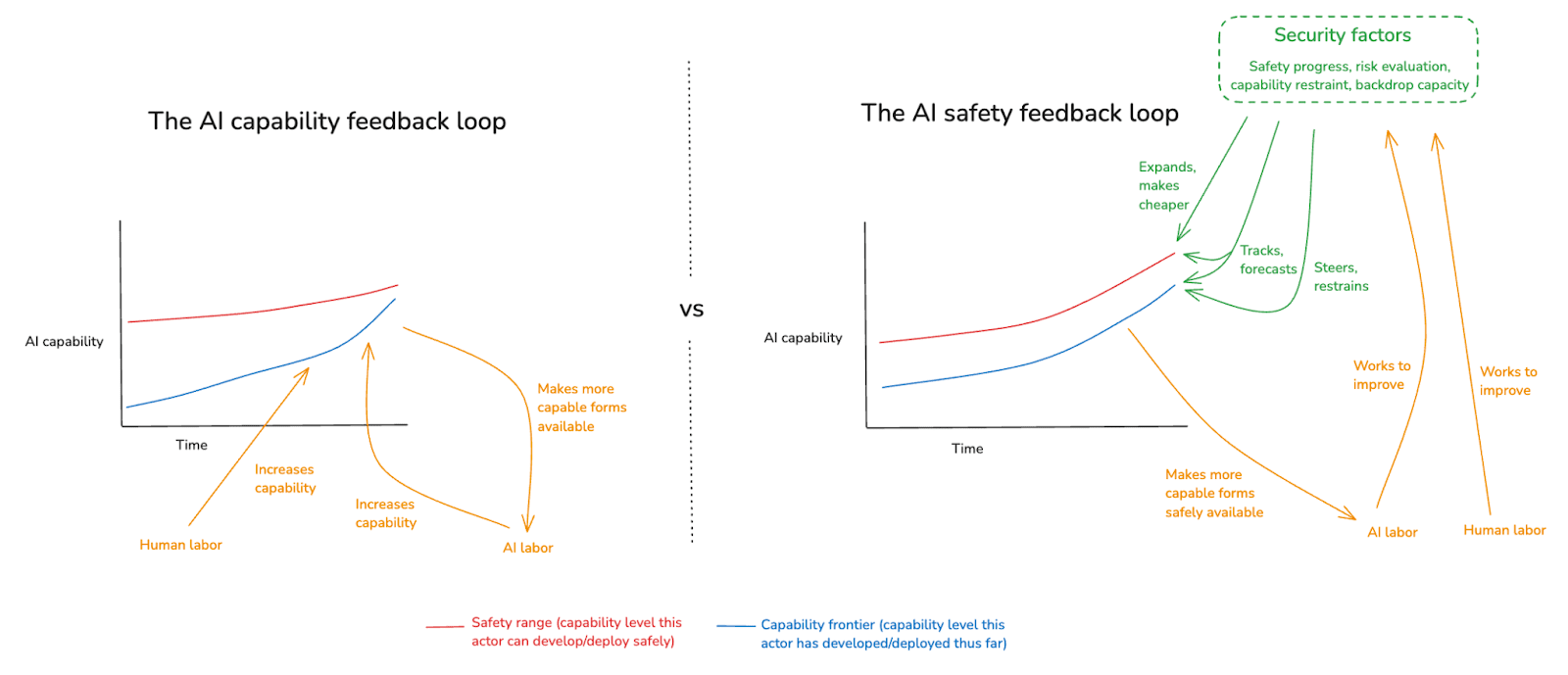
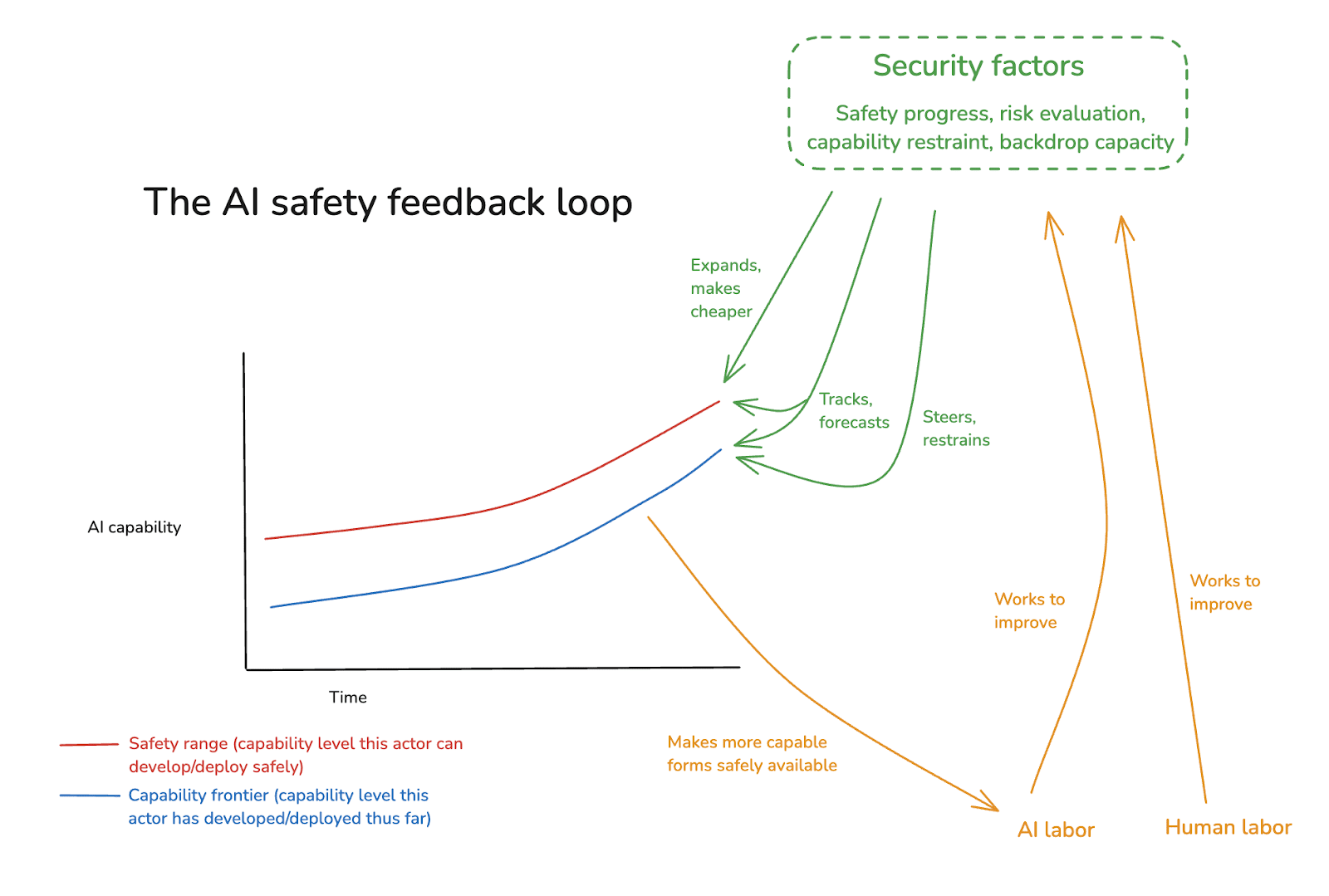
In my last essay, I offered a high-level framework for thinking about the path from here to safe superintelligence. This framework emphasized the role of three key “security factors” – namely:
- Safety progress: our ability to develop new levels of AI capability safely,
- Risk evaluation: our ability to track and forecast the level of risk that a given sort of AI capability development involves, and
- Capability restraint [...]
---
Outline:
(00:27) 1. Introduction and summary
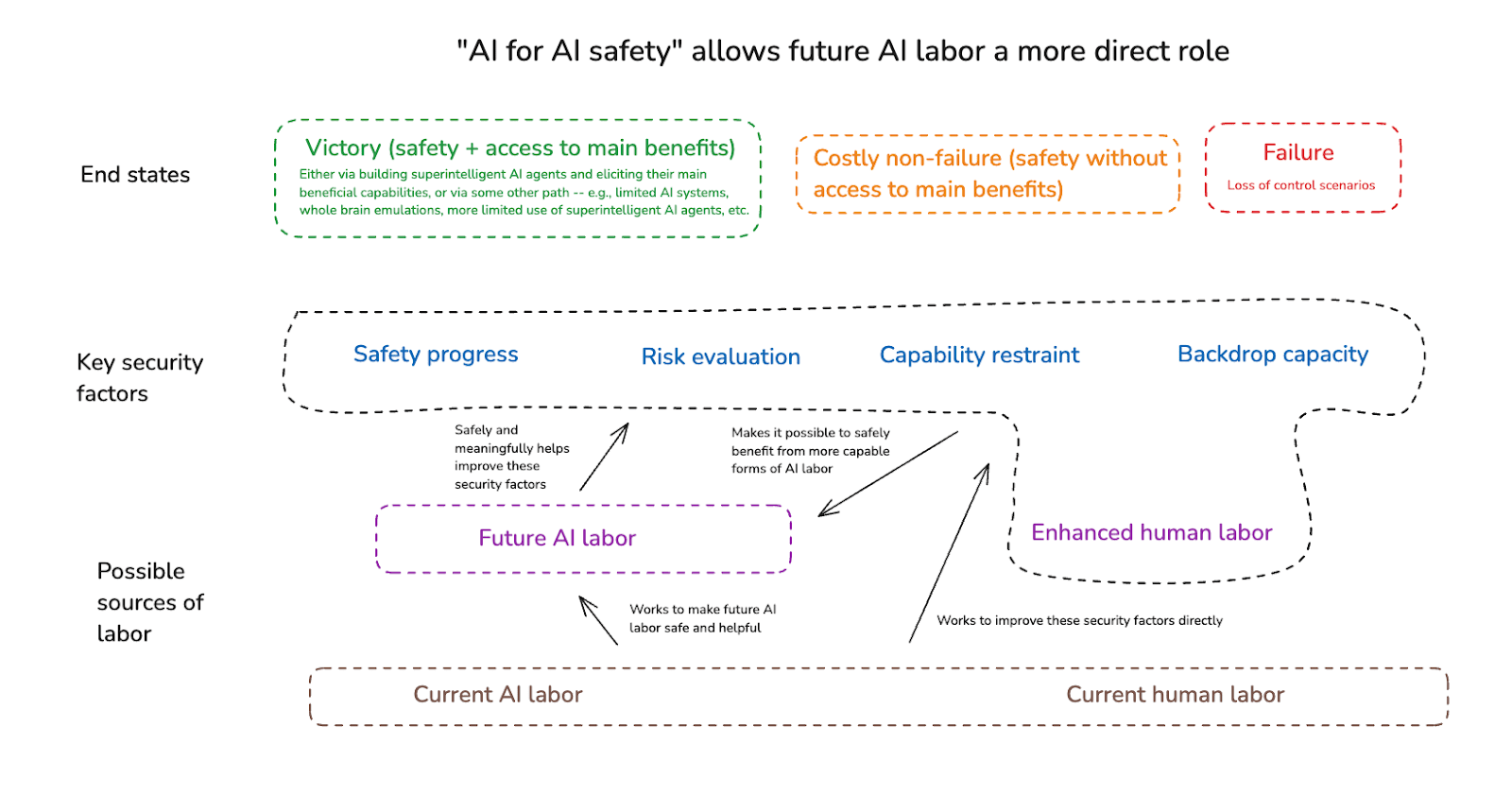
(03:50) 2. What is AI for AI safety?
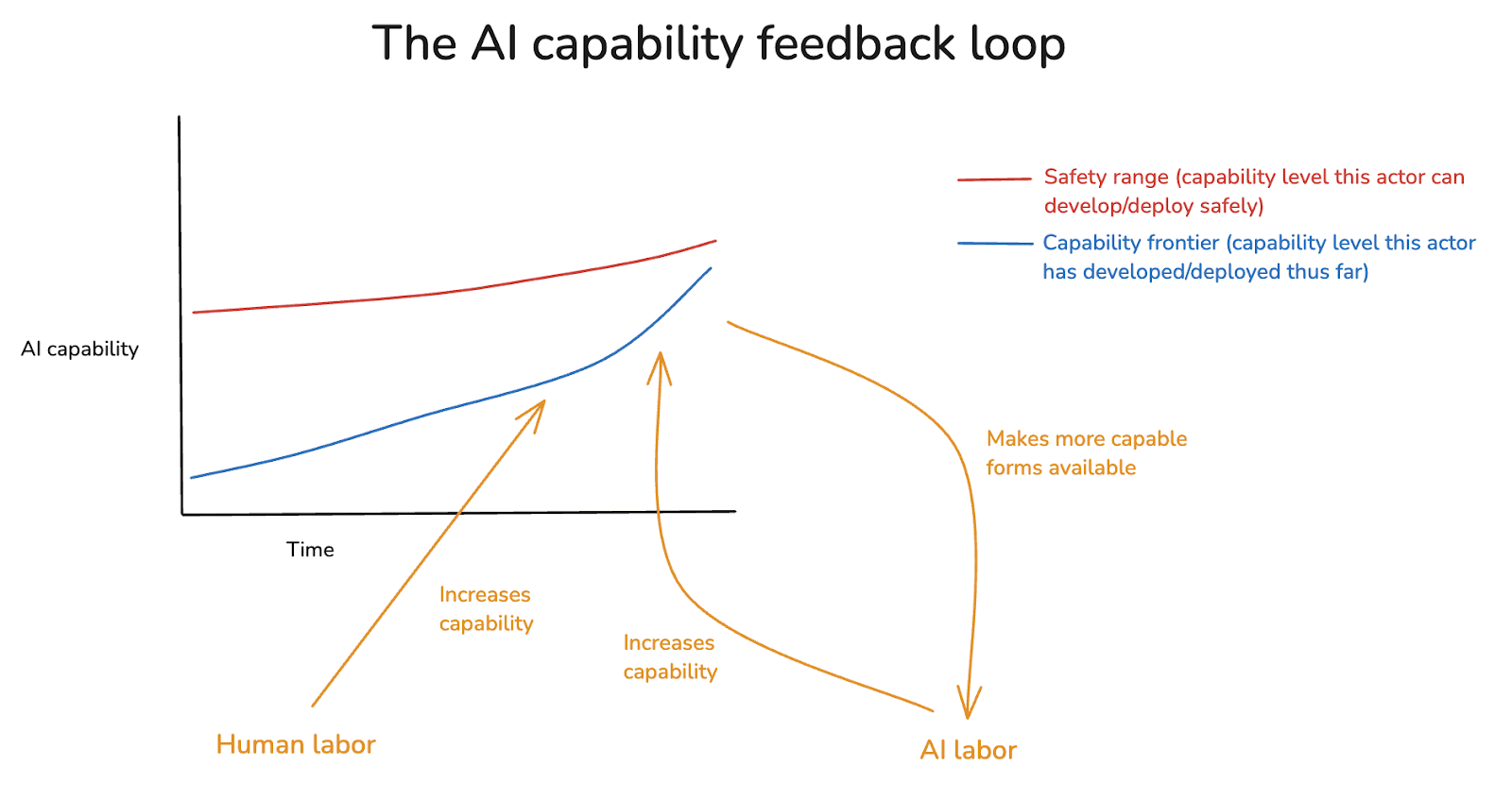
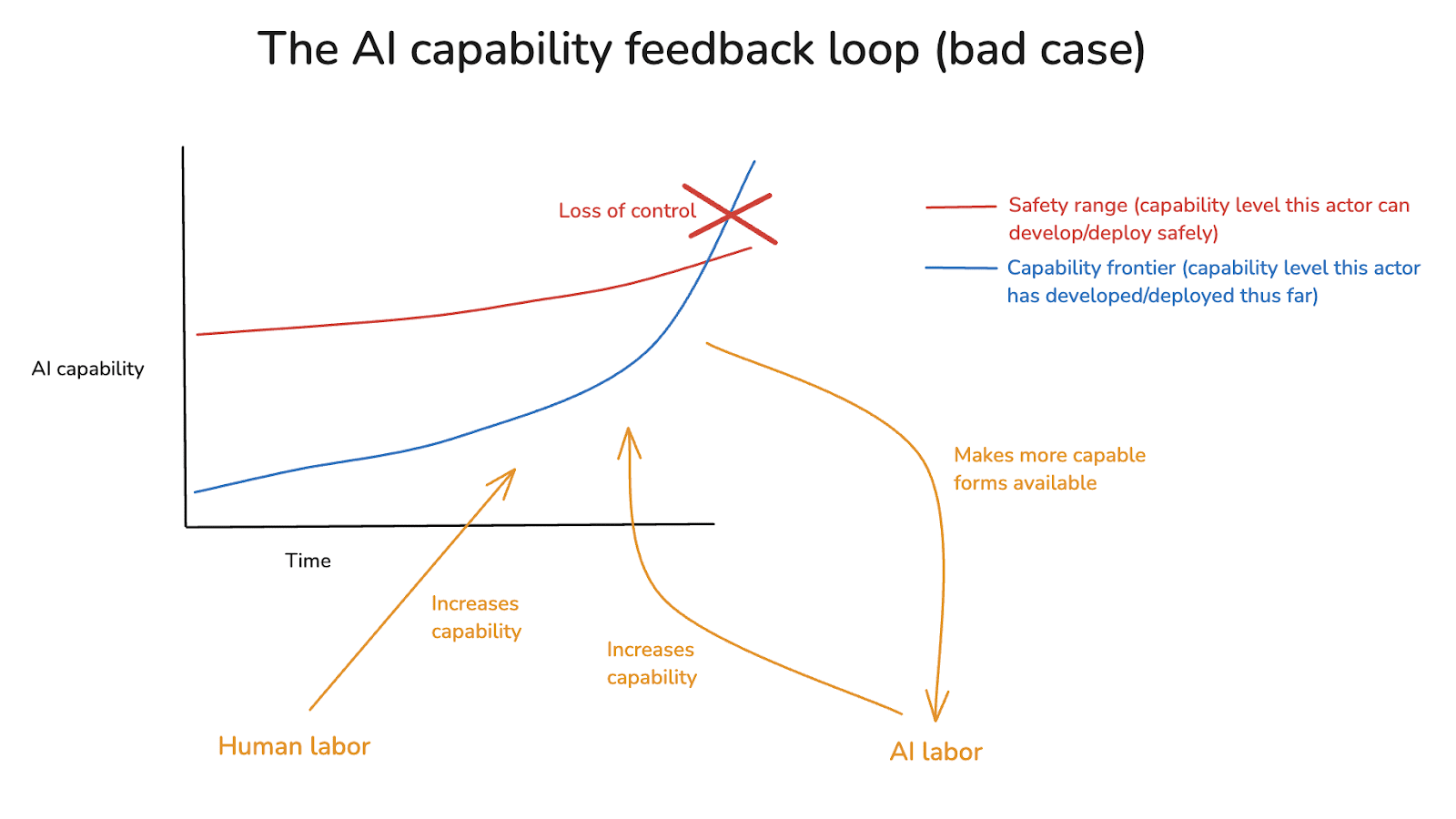
(11:50) 2.1 A tale of two feedback loops
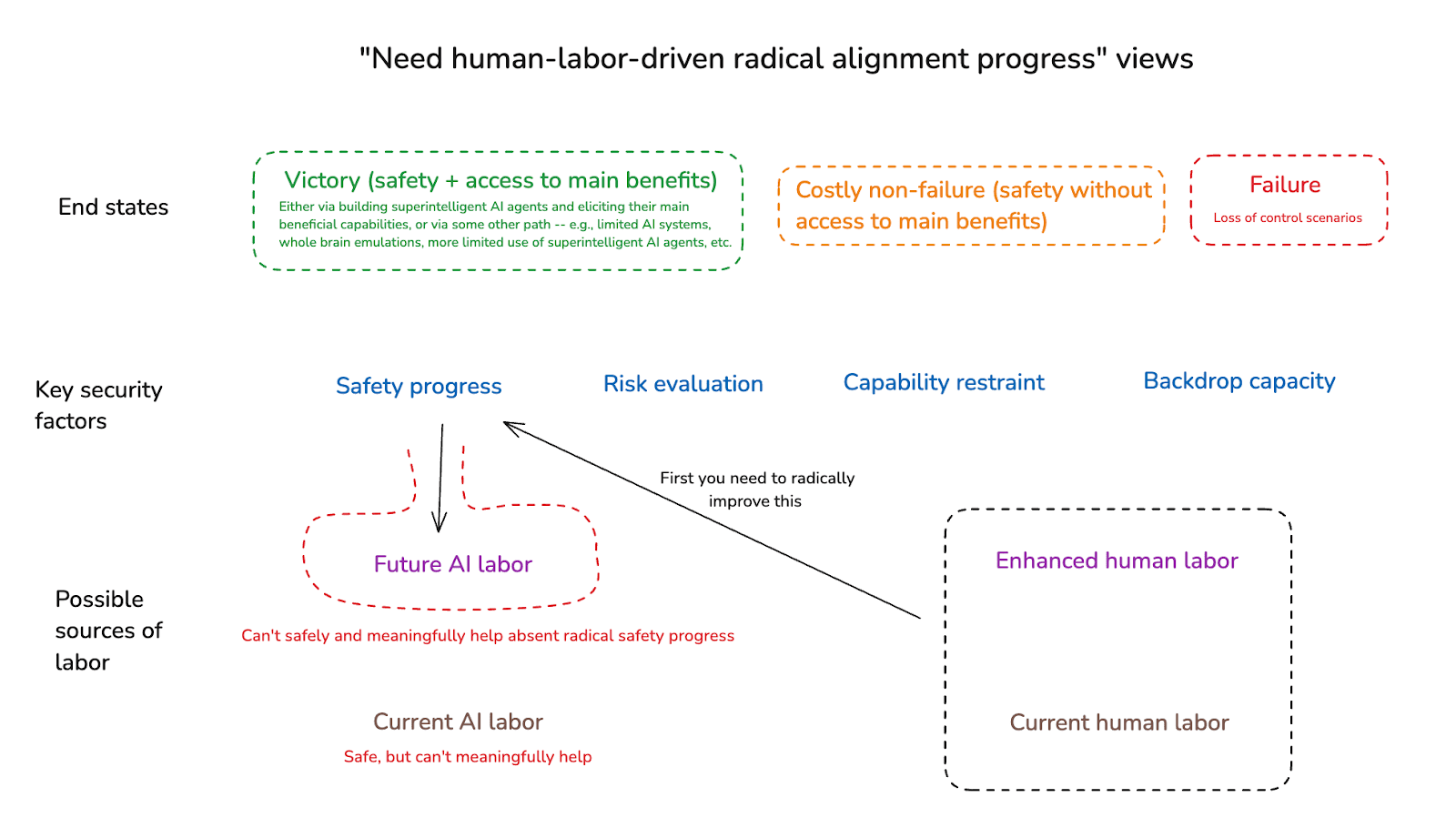
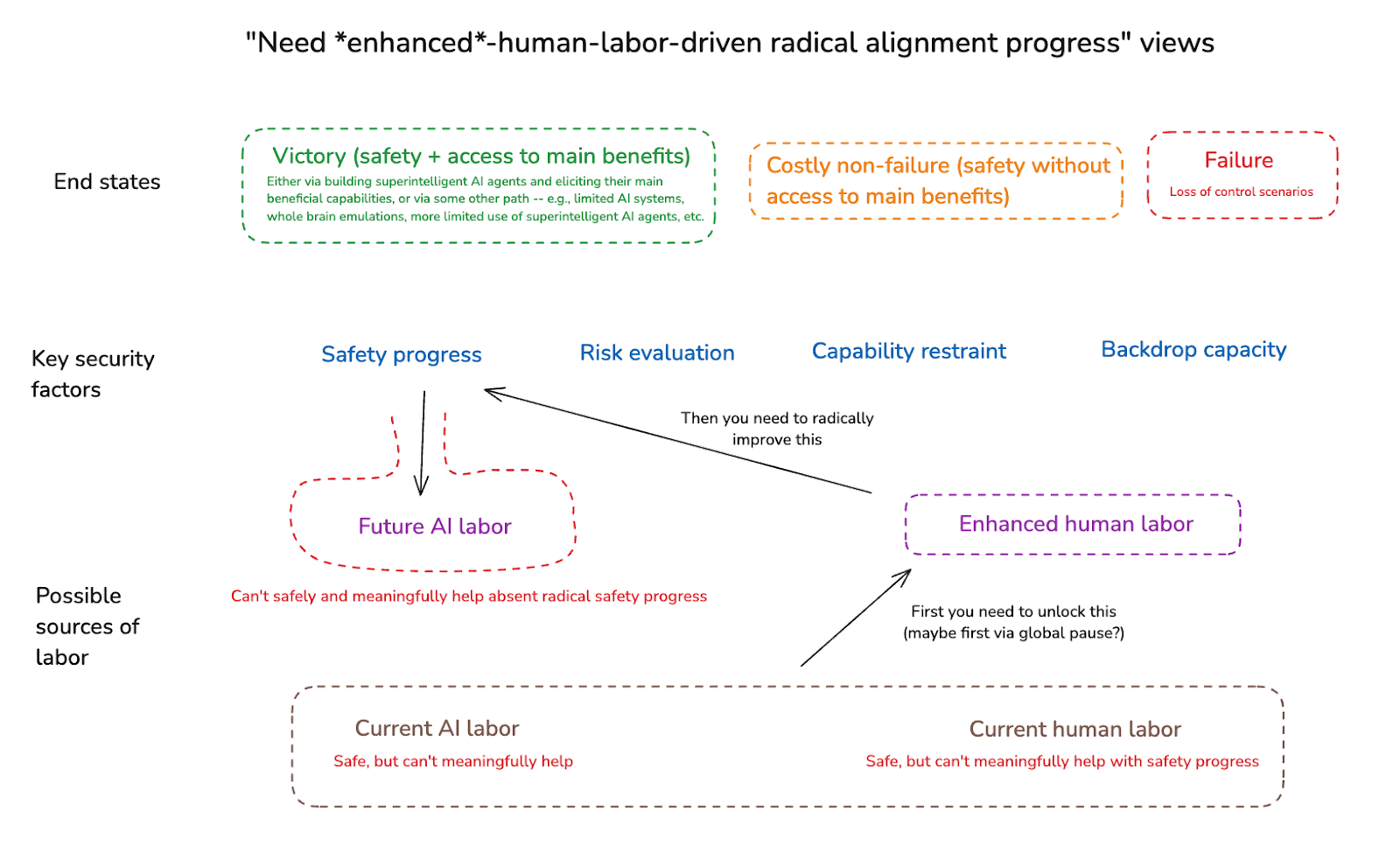
(13:58) 2.2 Contrast with need human-labor-driven radical alignment progress views
(16:05) 2.3 Contrast with a few other ideas in the literature
(18:32) 3. Why is AI for AI safety so important?
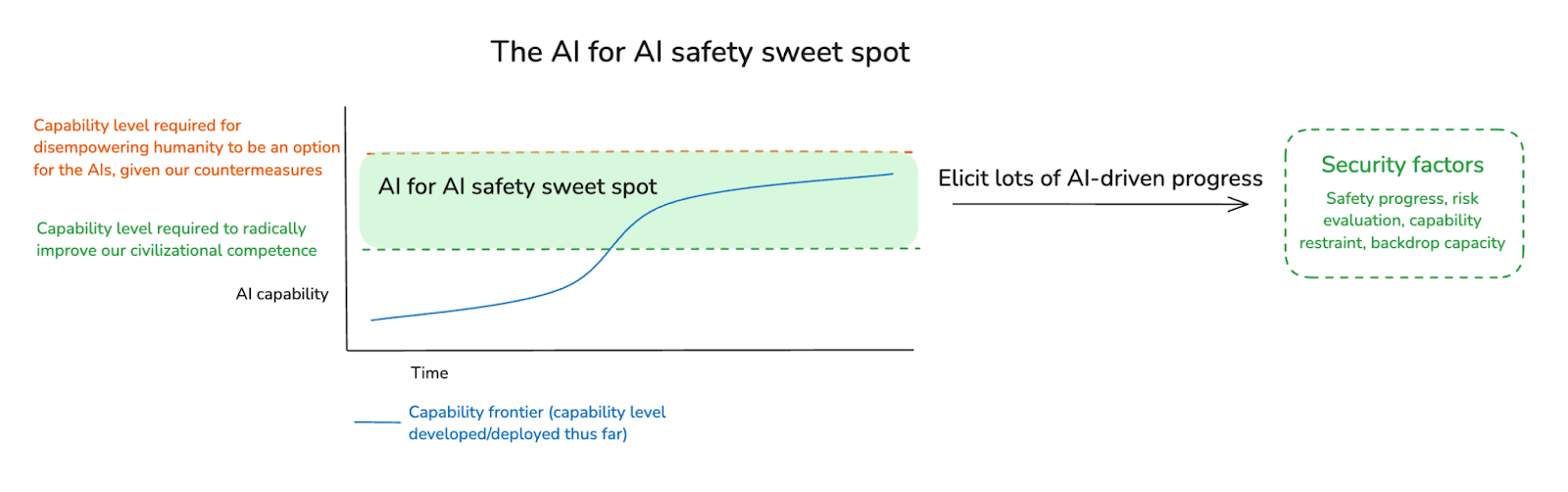
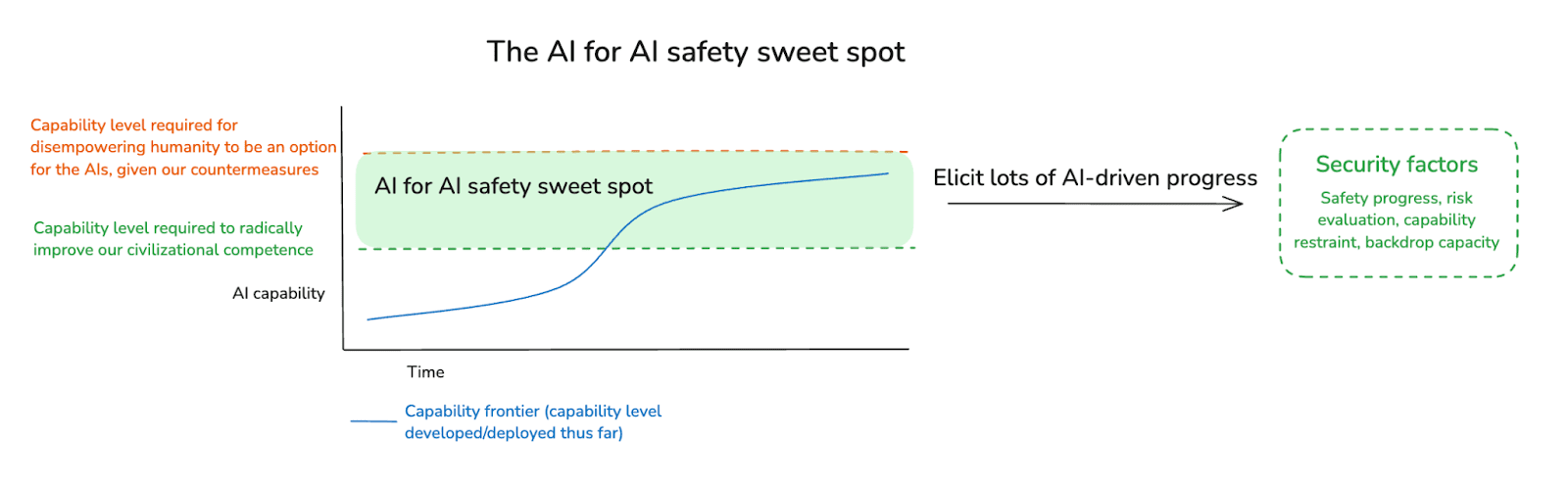
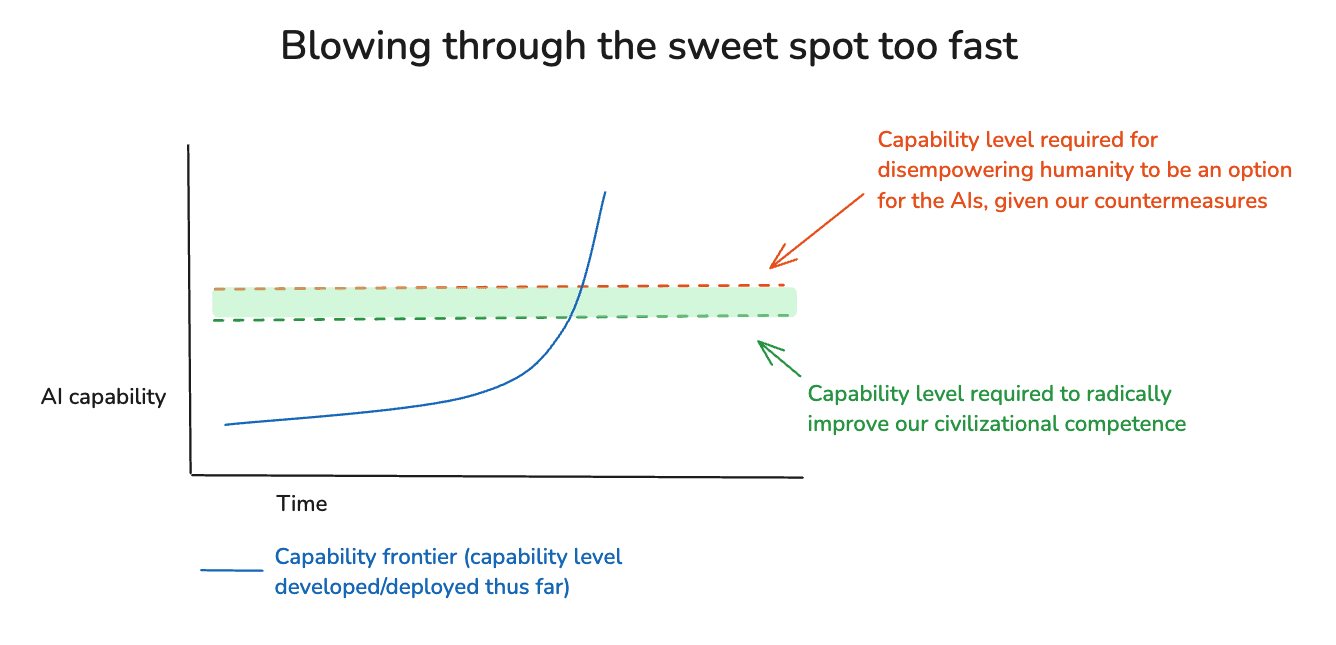
(21:56) 4. The AI for AI safety sweet spot
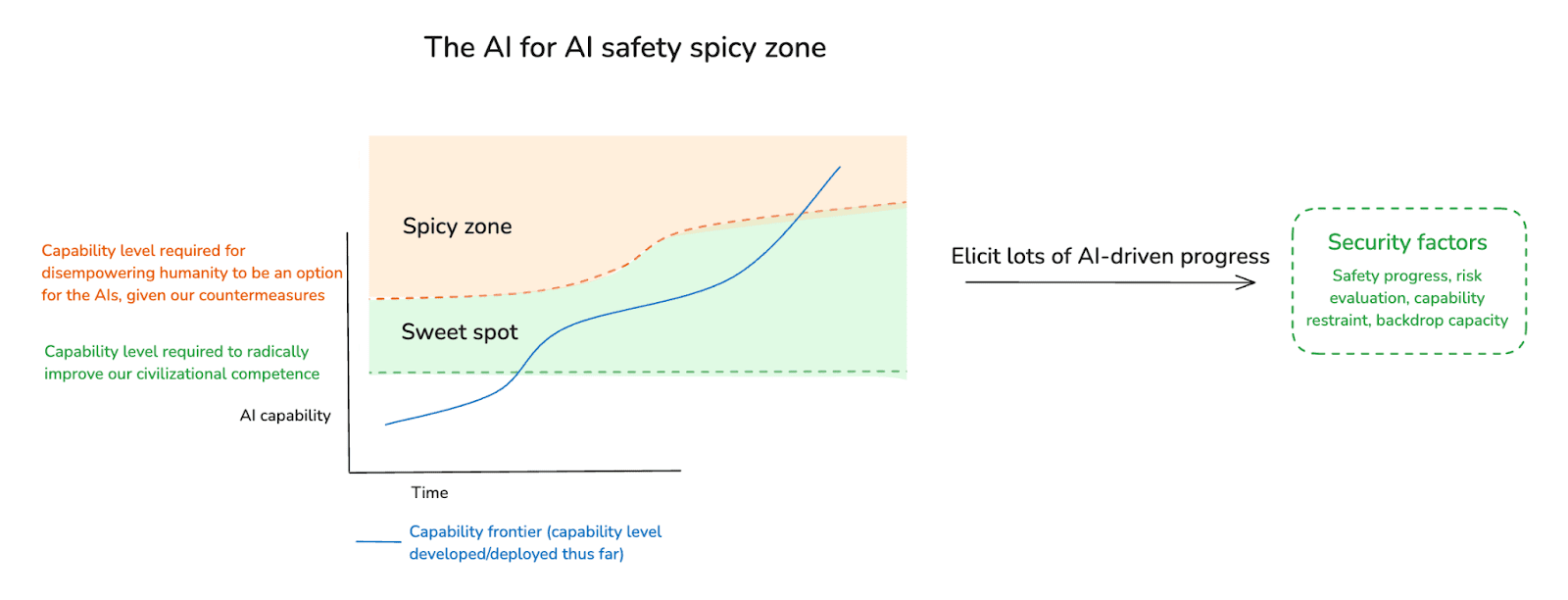
(26:09) 4.1 The AI for AI safety spicy zone
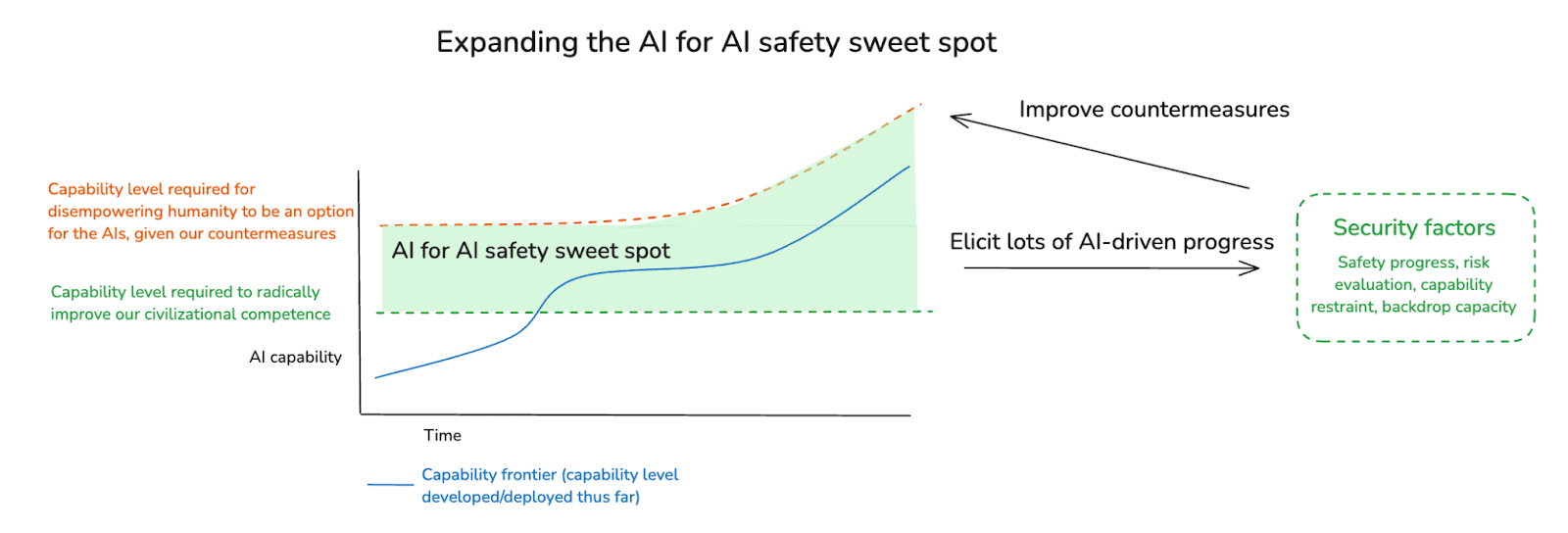
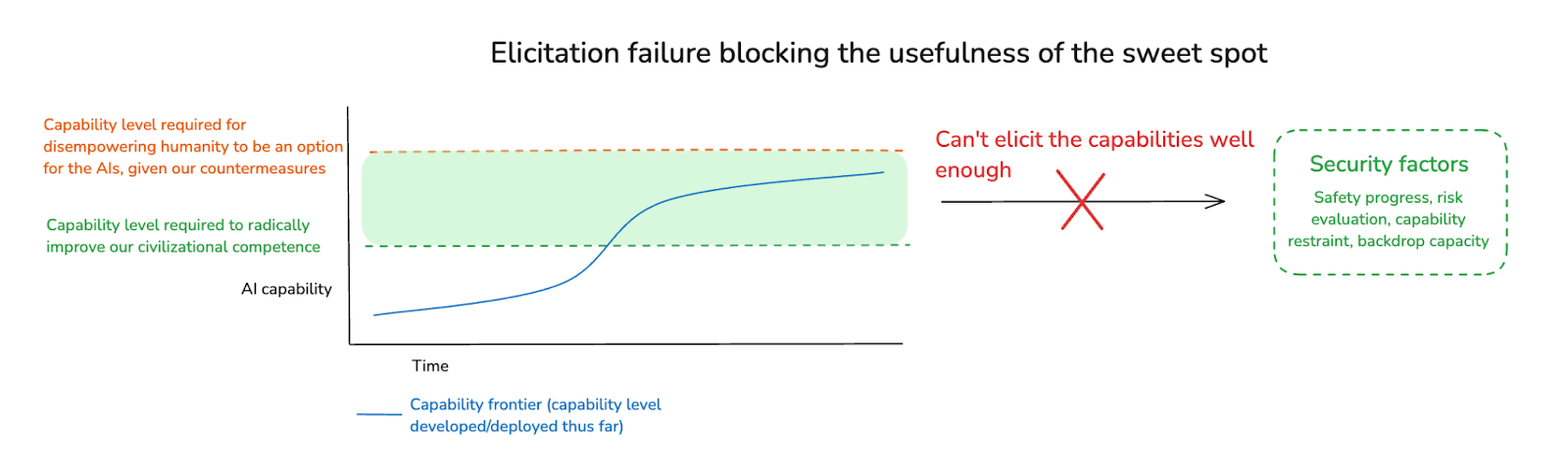
(28:07) 4.2 Can we benefit from a sweet spot?
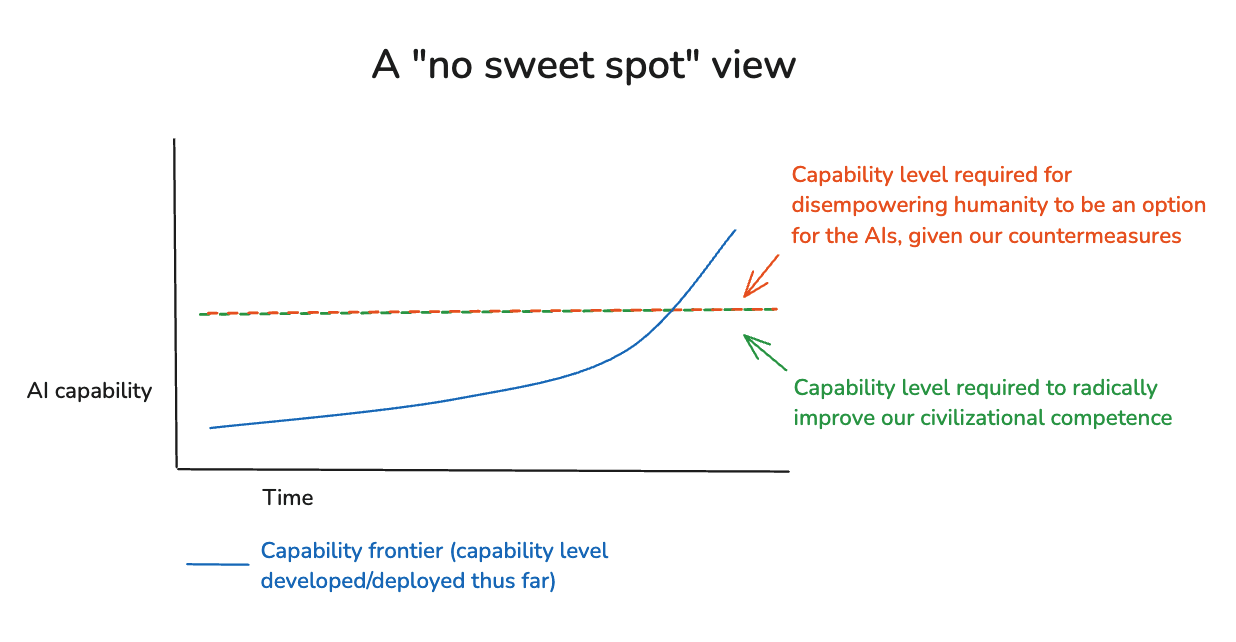
(29:56) 5. Objections to AI for AI safety
(30:14) 5.1 Three core objections to AI for AI safety
(32:00) 5.2 Other practical concerns
The original text contained 39 footnotes which were omitted from this narration.
---
First published:
March 14th, 2025
Source:
https://www.lesswrong.com/posts/F3j4xqpxjxgQD3xXh/ai-for-ai-safety
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00