Bra podcast
Sveriges mest populära poddar
“Anthropic, and taking ‘technical philosophy’ more seriously” by Raemon
21 min •
13 mars 2025
So, I have a lot of complaints about Anthropic, and about how EA / AI safety people often relate to Anthropic (i.e. treating the company as more trustworthy/good than makes sense).
At some point I may write up a post that is focused on those complaints.
But after years of arguing with Anthropic employees, and reading into the few public writing they've done, my sense is Dario/Anthropic-leadership are at least reasonably earnestly trying to do good things within their worldview.
So I want to just argue with the object-level parts of that worldview that I disagree with.
I think the Anthropic worldview is something like:
- Superalignment is probably not that hard to navigate.[1]
- Misuse by totalitarian regimes or rogue actors is reasonably likely by default, and very bad.
- AGI founded in The West would not be bad in the ways that totalitarian regimes would be.
- Quick empiricism [...]
---
Outline:
(03:08) I: Arguments for Technical Philosophy
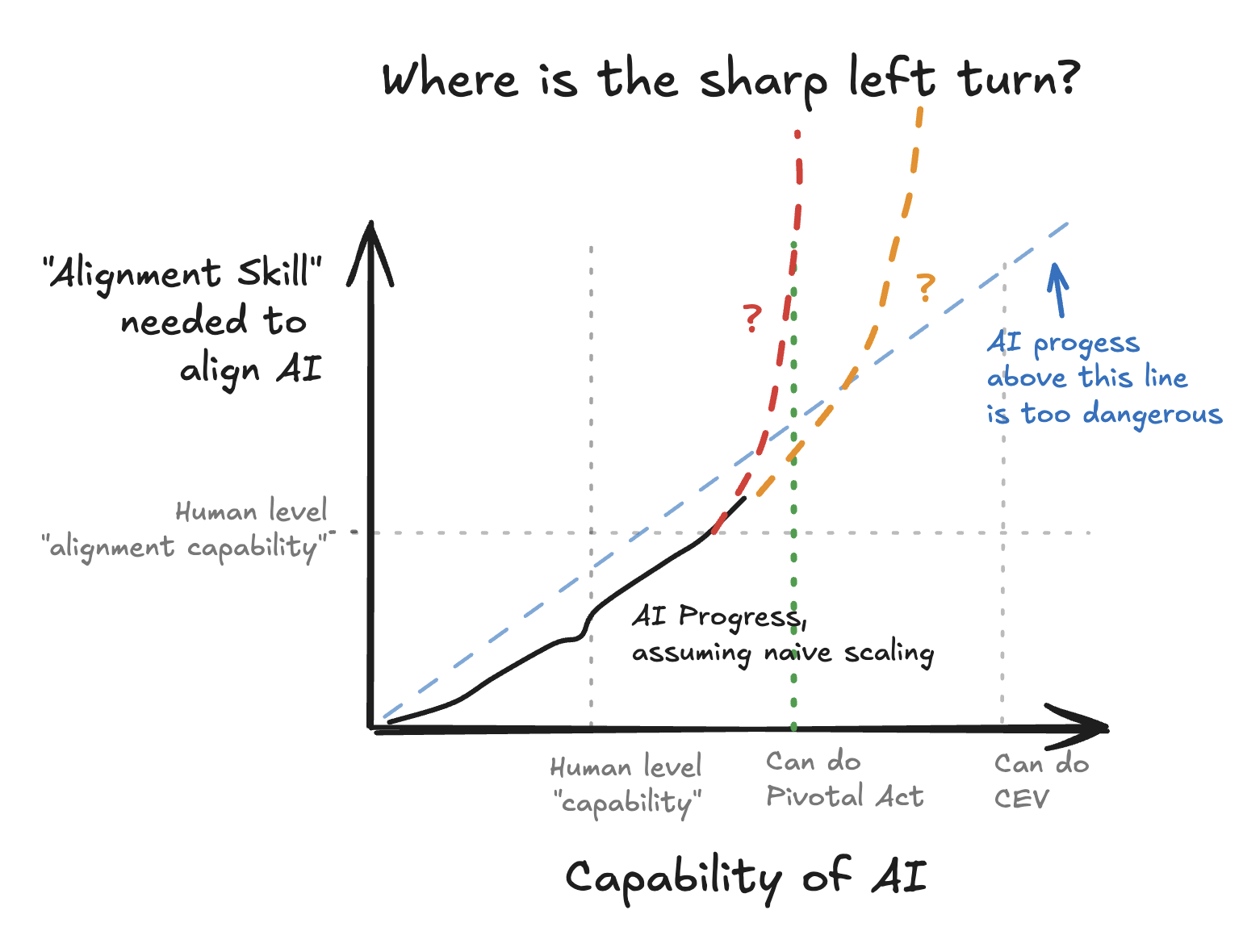
(06:00) 10-30 years of serial research, or extreme philosophical competence.
(07:16) Does your alignment process safely scale to infinity?
(11:14) Okay, but what does the alignment difficulty curve look like at the point where AI is powerful enough to start being useful for Acute Risk Period reduction?
(12:58) Are there any pivotal acts that arent philosophically loaded?
(15:17) Your org culture needs to handle the philosophy
(17:48) Also, like, you should be way more pessimistic about how this is organizationally hard
(18:59) Listing Cruxes and Followup Debate
The original text contained 8 footnotes which were omitted from this narration.
---
First published:
March 13th, 2025
Source:
https://www.lesswrong.com/posts/7uTPrqZ3xQntwQgYz/untitled-draft-7csk
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00