Bra podcast
Sveriges mest populära poddar
“Can we safely automate alignment research?” by Joe Carlsmith
118 min •
30 april 2025
(This is the fifth essay in a series that I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.
Podcast version (read by the author) here, or search for "Joe Carlsmith Audio" on your podcast app.
See also here for video and transcript of a talk on this topic that I gave at Anthropic in April 2025. And see here for slides.)
1. Introduction
In my last essay, I argued that we should try extremely hard to use AI labor to improve our civilization's capacity to handle the alignment problem – a project I called “AI for AI safety.” In this essay, I want to look in more [...]
---
Outline:
(00:43) 1. Introduction
(03:16) 1.1 Executive summary
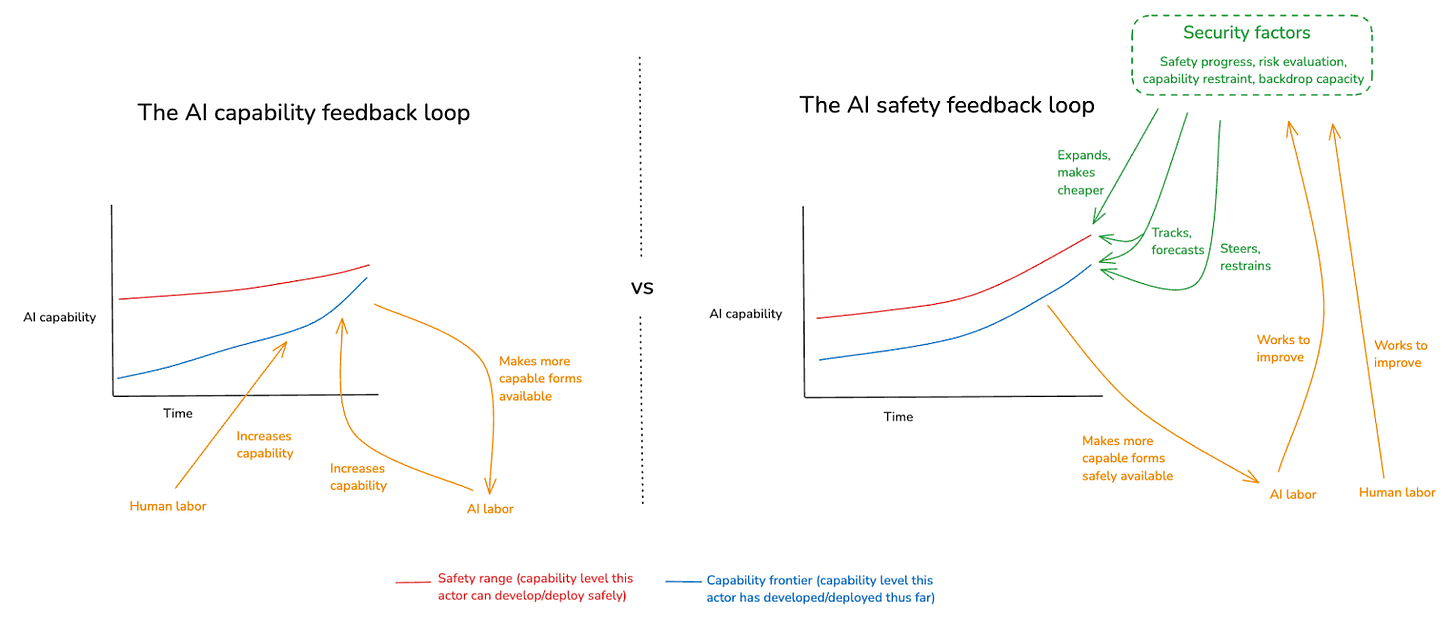
(14:11) 2. Why is automating alignment research so important?
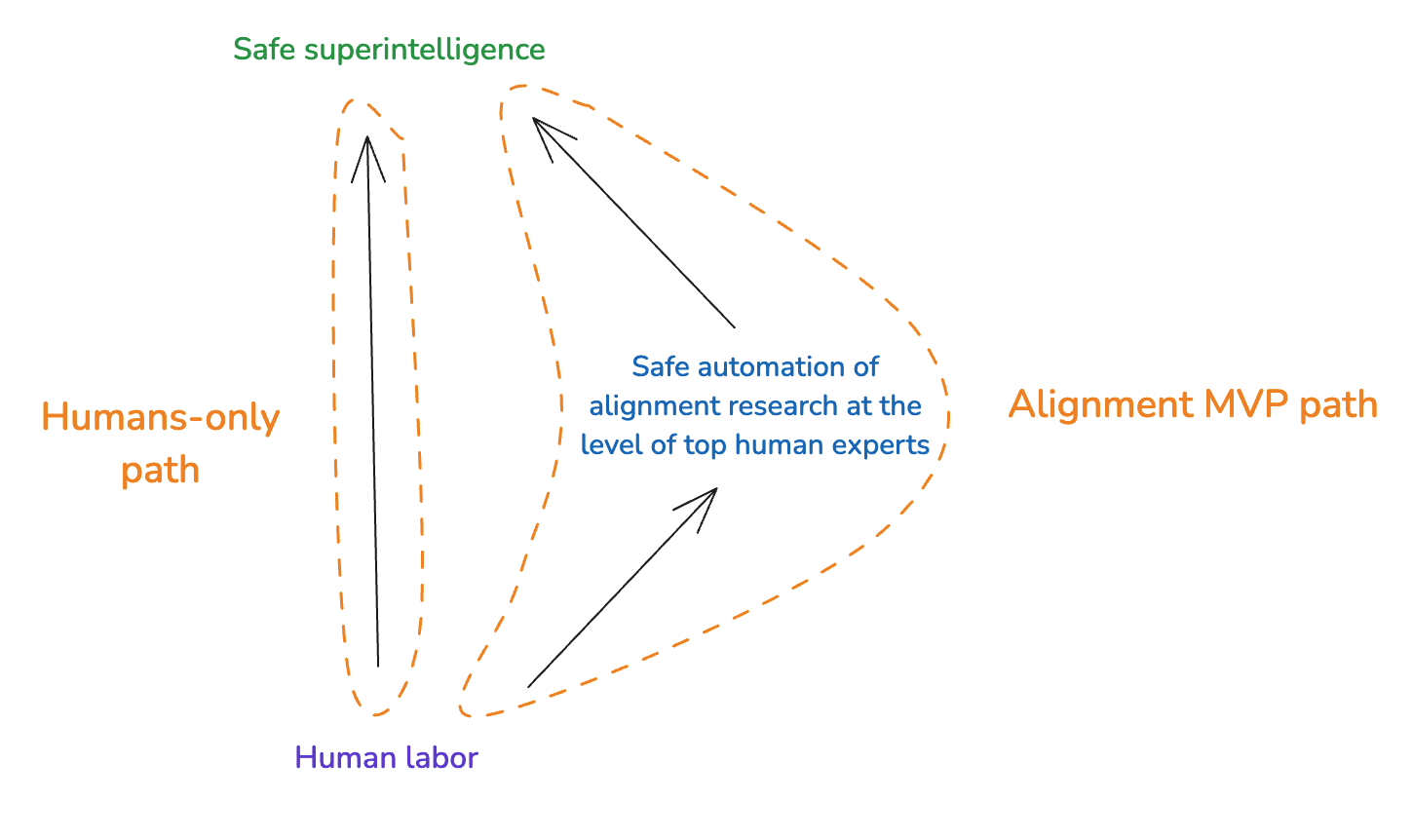
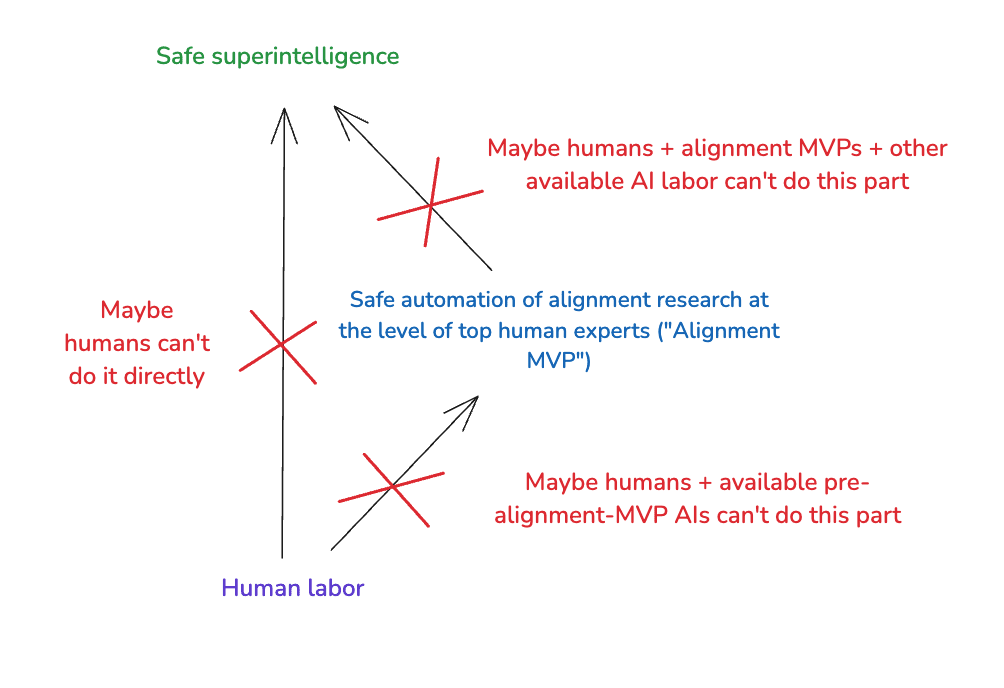
(16:14) 3. Alignment MVPs
(19:54) 3.1 What if neither of these approaches are viable?
(21:55) 3.2 Alignment MVPs don't imply hand-off
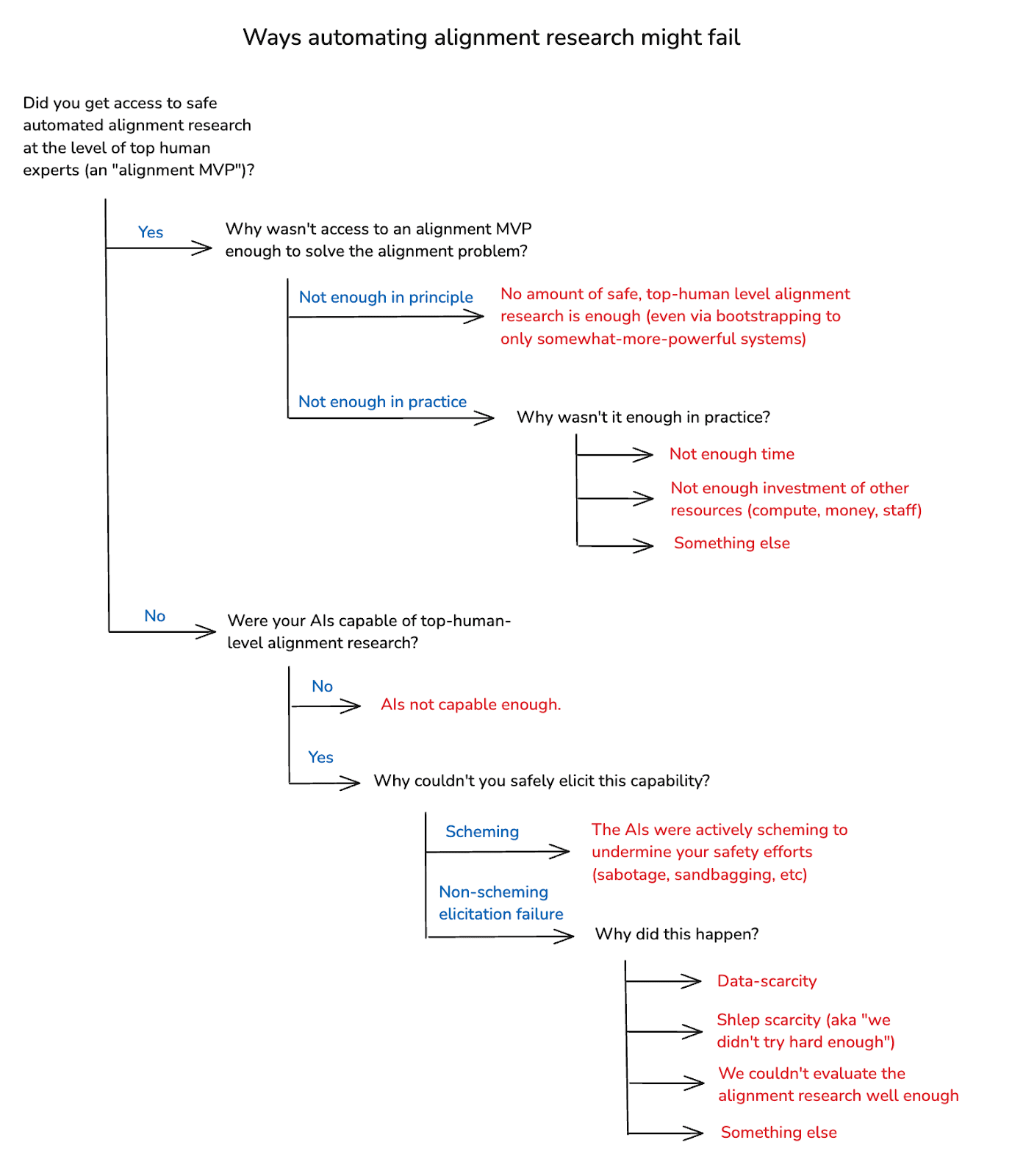
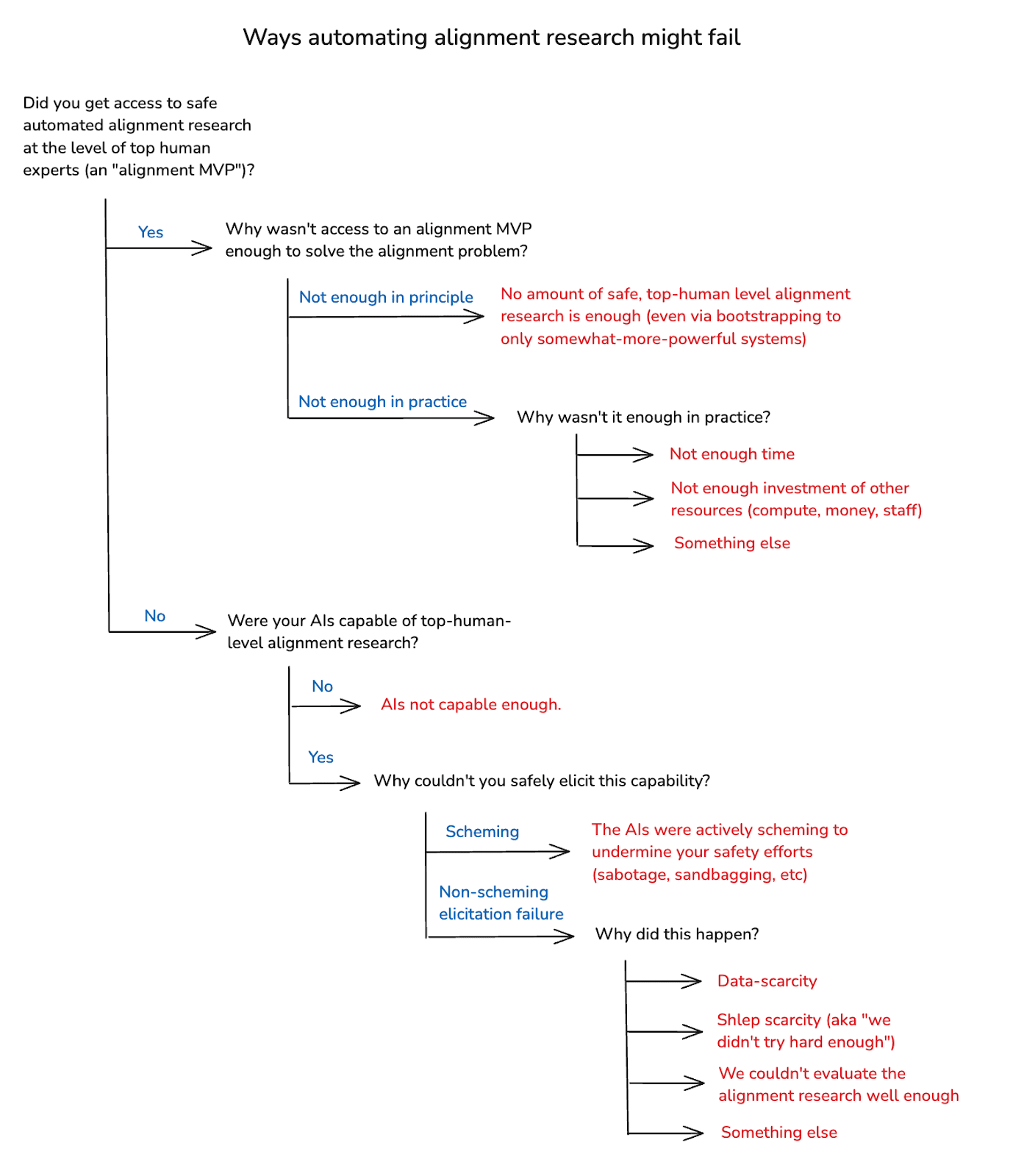
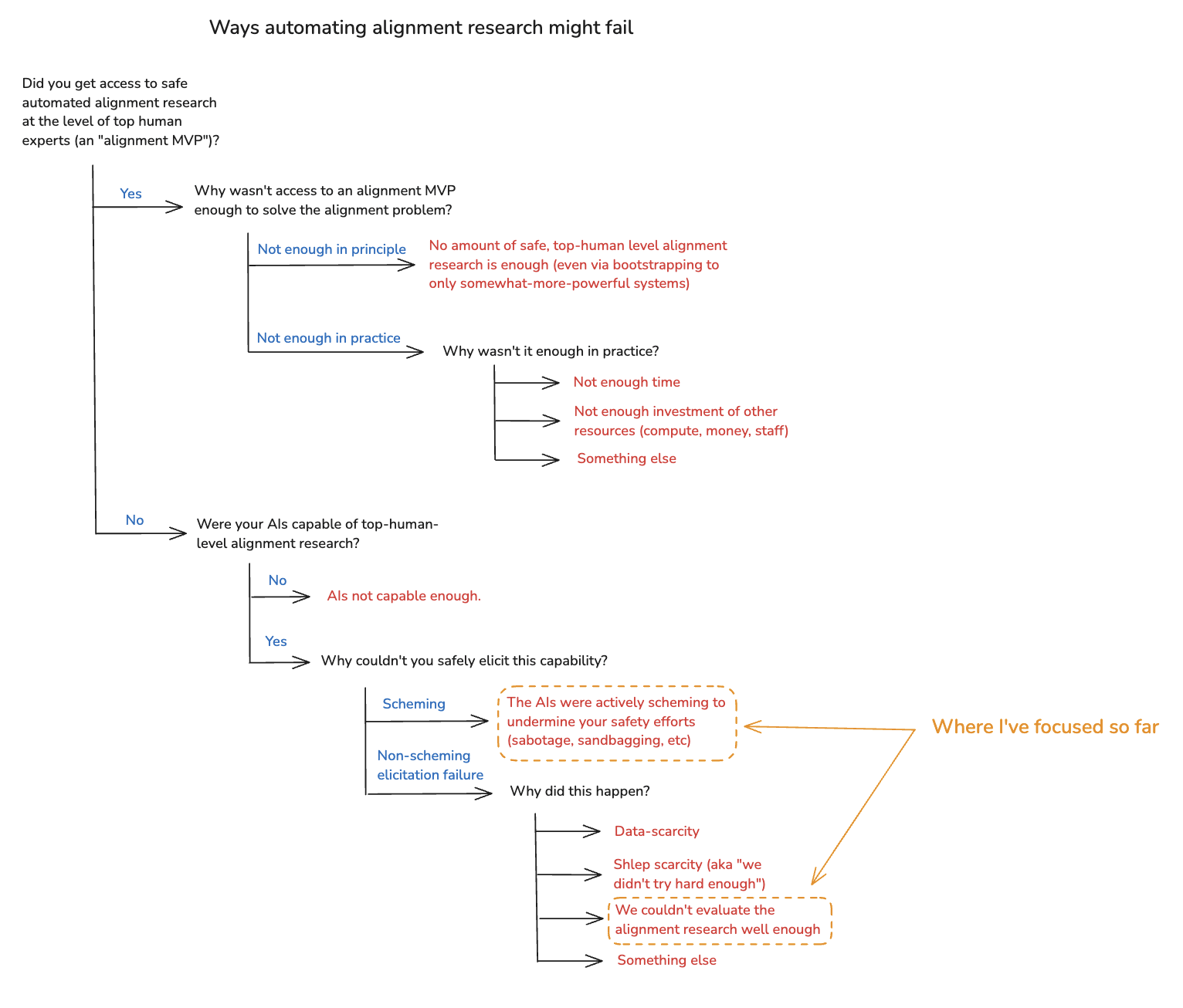
(23:41) 4. Why might automated alignment research fail?
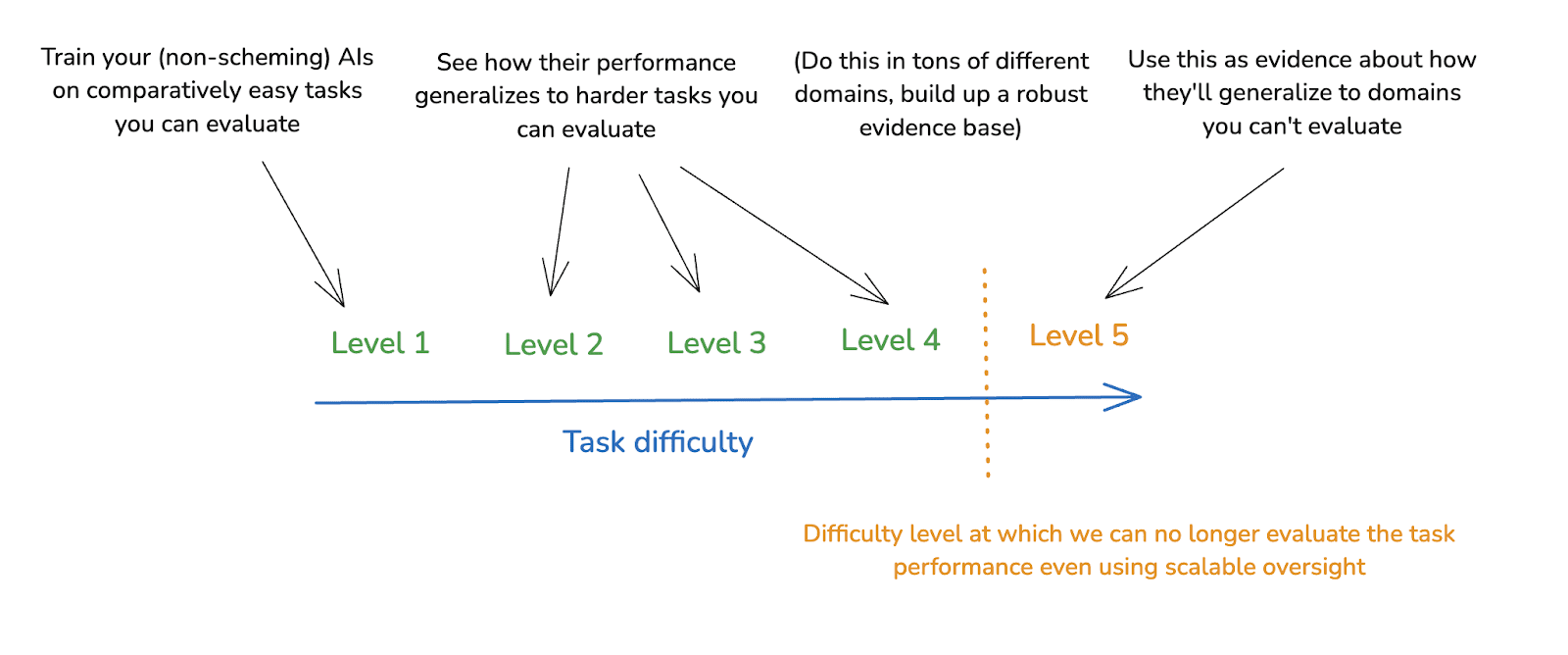
(29:25) 5. Evaluation failures
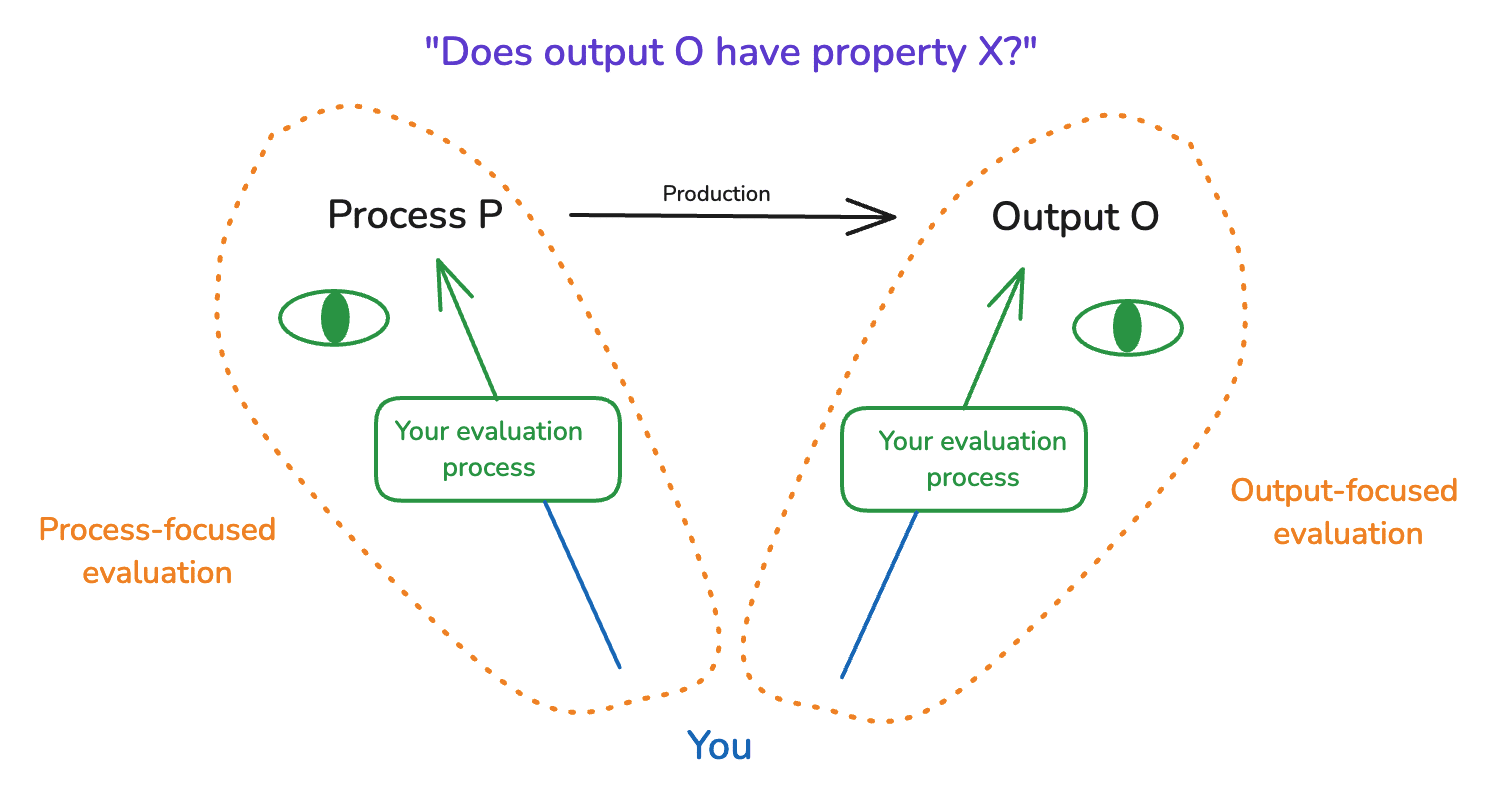
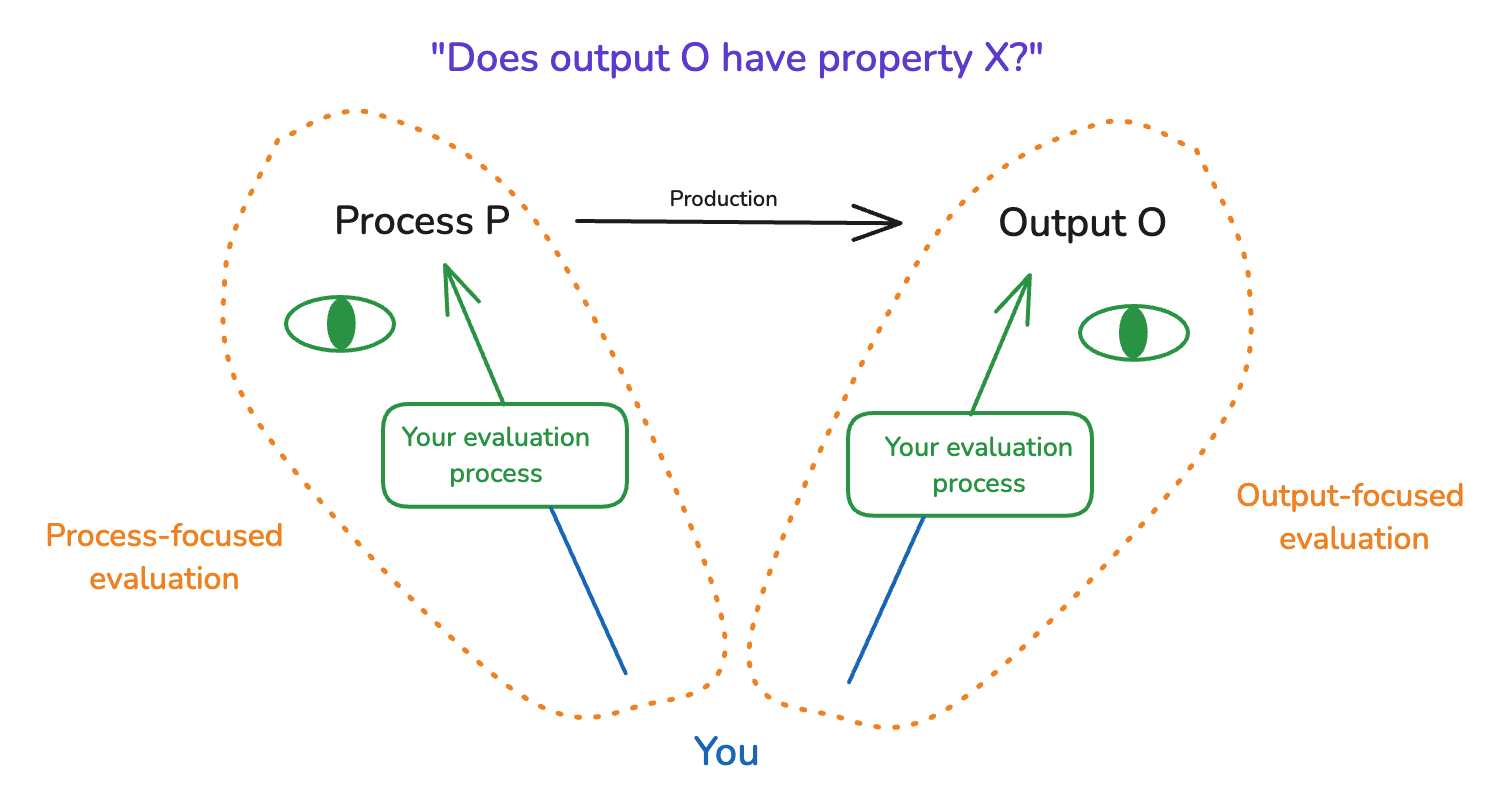
(30:46) 5.1 Output-focused and process-focused evaluation
(34:09) 5.2 Human output-focused evaluation
(36:11) 5.3 Scalable oversight
(39:29) 5.4 Process-focused techniques
(43:14) 6 Comparisons with other domains
(44:04) 6.1 Taking comfort in general capabilities problems?
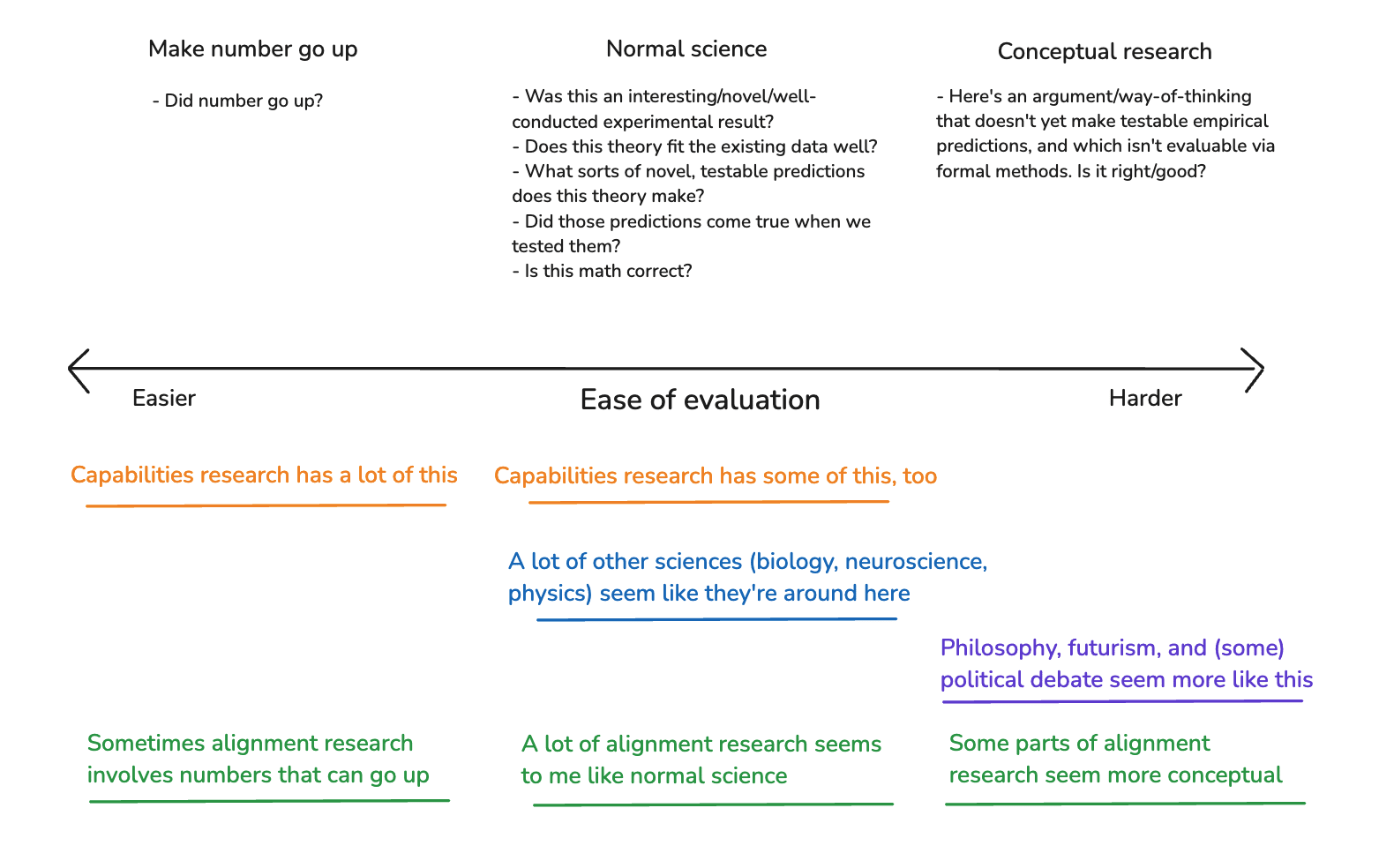
(49:18) 6.2 How does our evaluation ability compare in these different domains?
(49:45) 6.2.1 Number go up
(50:57) 6.2.2 Normal science
(57:55) 6.2.3 Conceptual research
(01:04:10) 7. How much conceptual alignment research do we need?
(01:04:36) 7.1 How much for building superintelligence?
(01:05:25) 7.2 How much for building an alignment MVP?
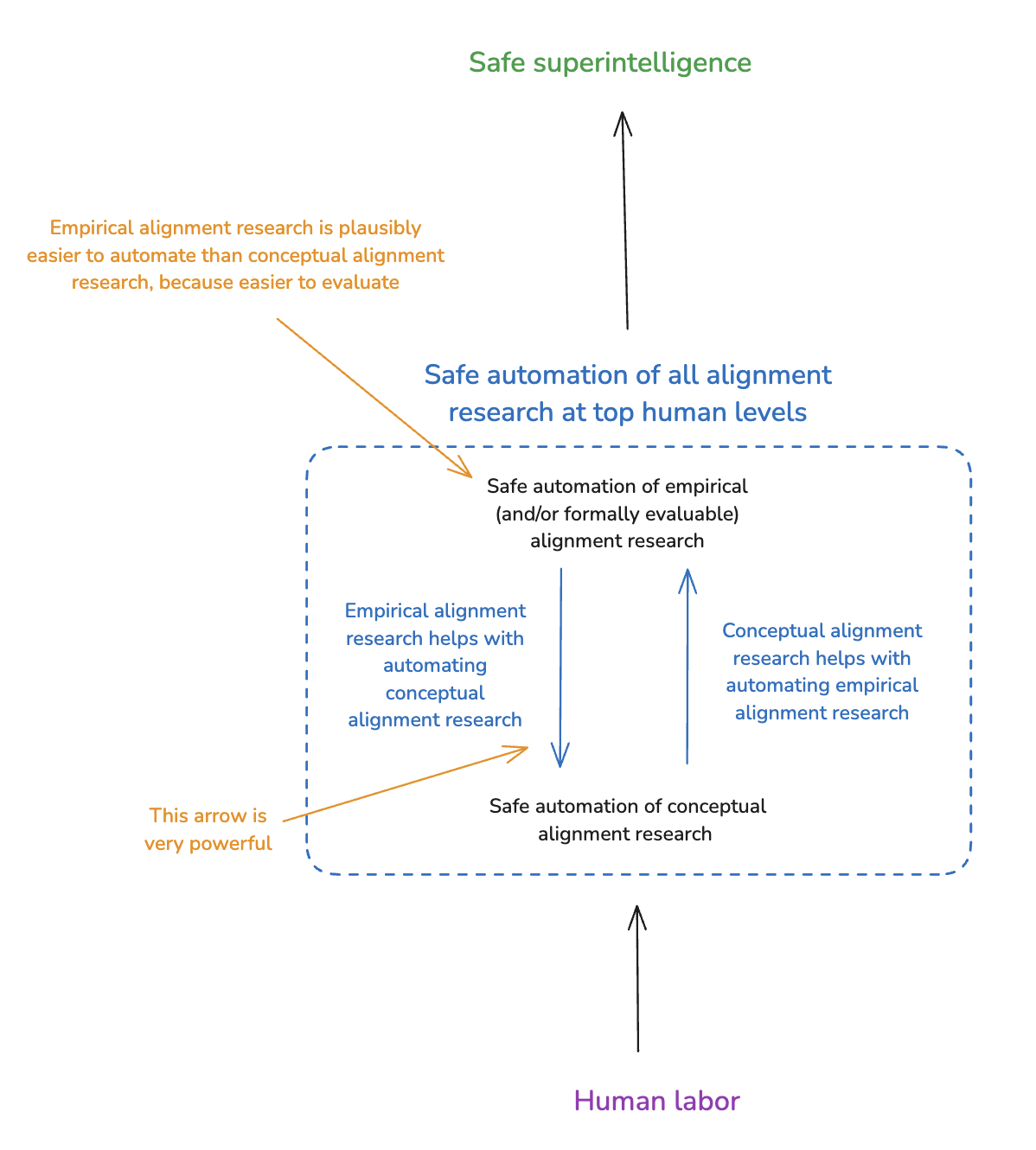
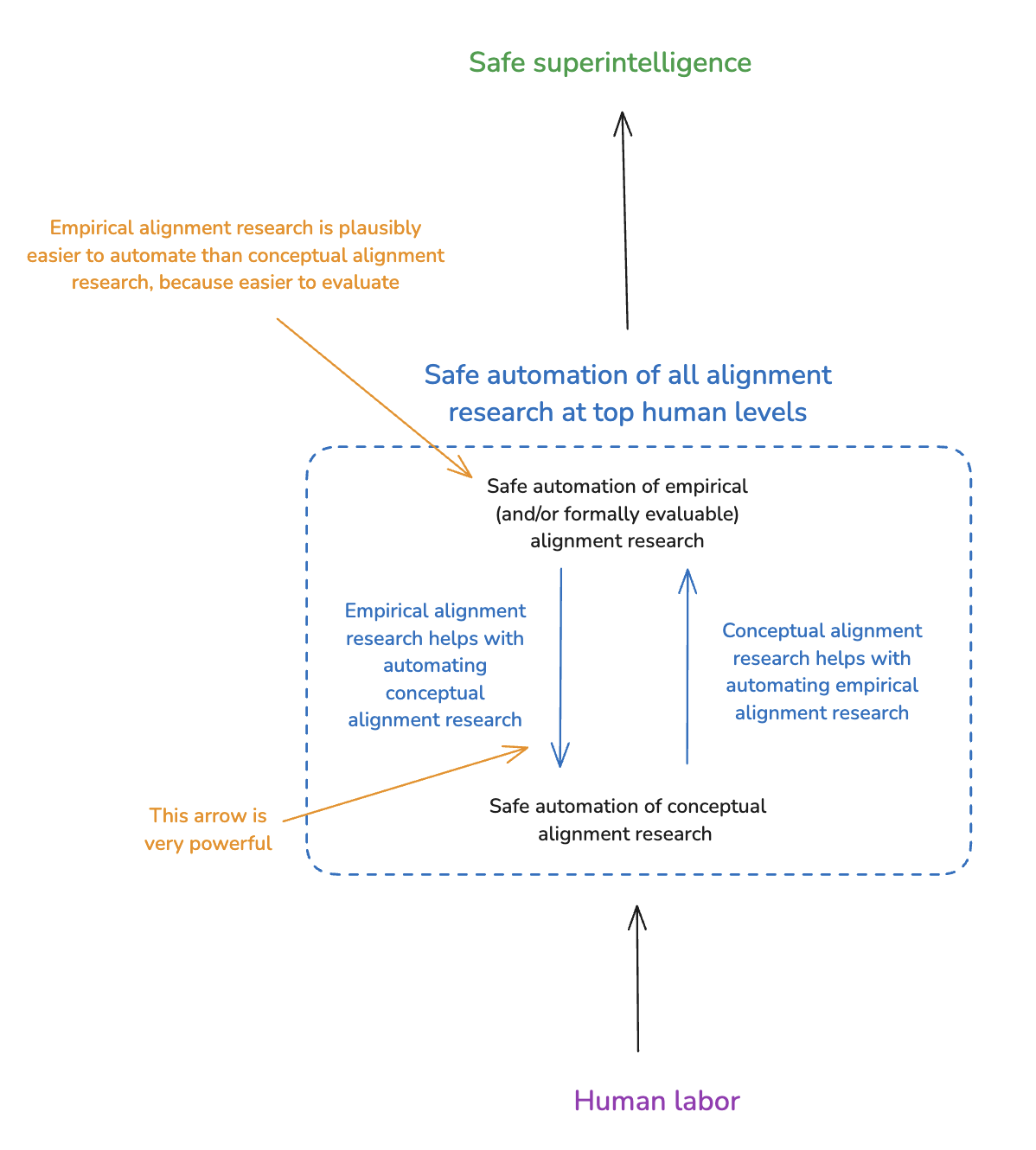
(01:07:42) 8. Empirical alignment research is extremely helpful for automating conceptual alignment research
(01:09:32) 8.1 Automated empirical research on scalable oversight
(01:14:21) 8.2 Automated empirical research on process-focused evaluation methods
(01:19:24) 8.3 Other ways automated empirical alignment research can be helpful
(01:20:44) 9. What about scheming?
(01:24:20) 9.1 Will AIs capable of top-human-level alignment research be schemers by default?
(01:26:41) 9.2 If these AIs would be schemers by default, can we detect and prevent this scheming?
(01:28:43) 9.3 Can we elicit safe alignment research from scheming AIs?
(01:32:09) 10. Resource problems
(01:35:54) 11. Alternatives to automating alignment research
(01:39:30) 12. Conclusion
(01:41:29) Appendix 1: How do these failure modes apply to other sorts of AI for AI safety?
(01:43:55) Appendix 2: Other practical concerns not discussed in the main text
(01:48:21) Appendix 3: On various arguments for the inadequacy of empirical alignment research
(01:55:50) Appendix 4: Does using AIs for alignment research require that they engage with too many dangerous topics/domains?
The original text contained 64 footnotes which were omitted from this narration.
---
First published:
April 30th, 2025
Source:
https://www.lesswrong.com/posts/nJcuj4rtuefeTRFHp/can-we-safely-automate-alignment-research
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00