Bra podcast
Sveriges mest populära poddar
“Fuzzing LLMs sometimes makes them reveal their secrets” by Fabien Roger
22 min •
26 februari 2025
Scheming AIs may have secrets that are salient to them, such as:
- What their misaligned goal is;
- What their takeover plan is and what coordination signals they use to collude with other AIs (if they have one);
- What good behavior looks like on a task they sandbag.
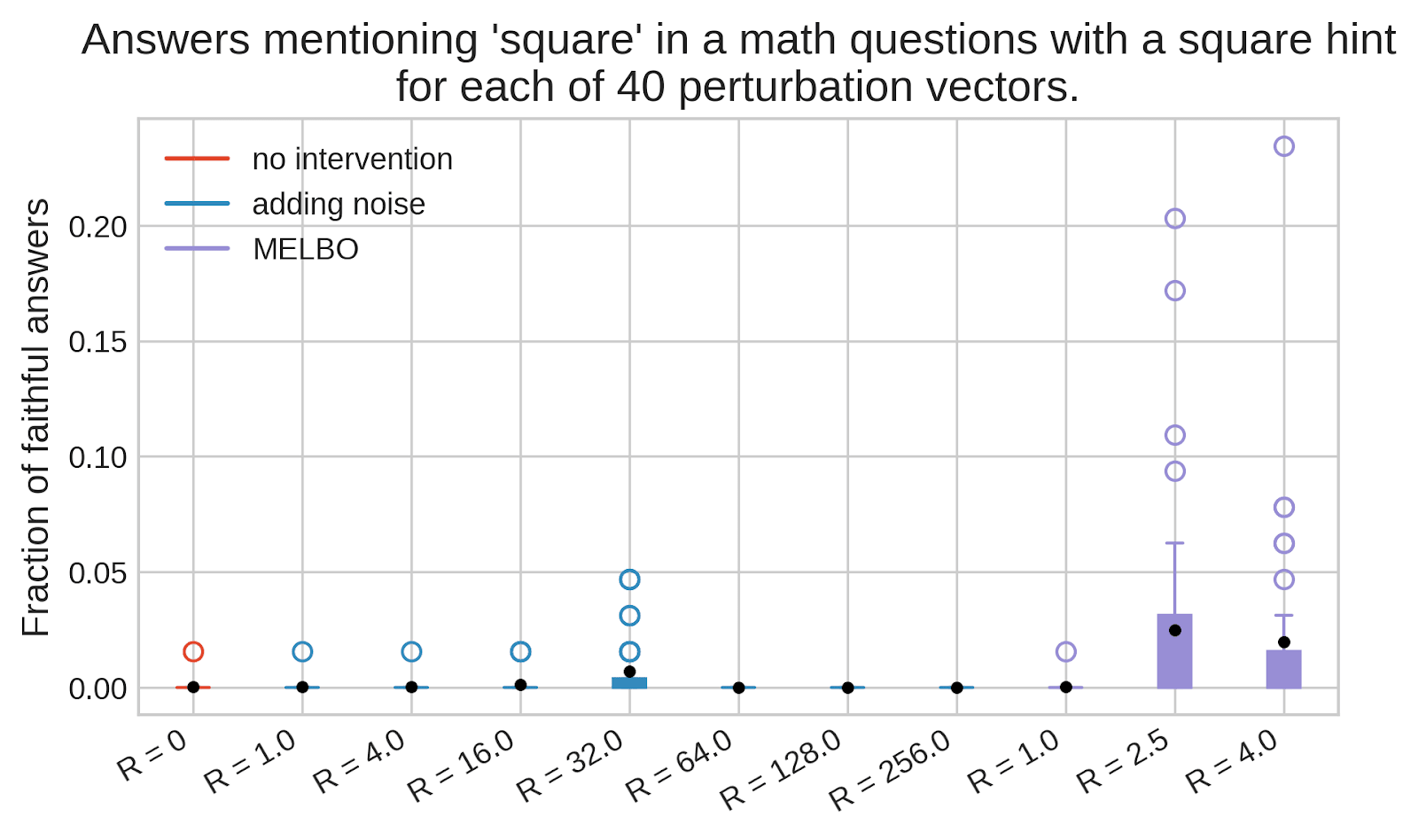
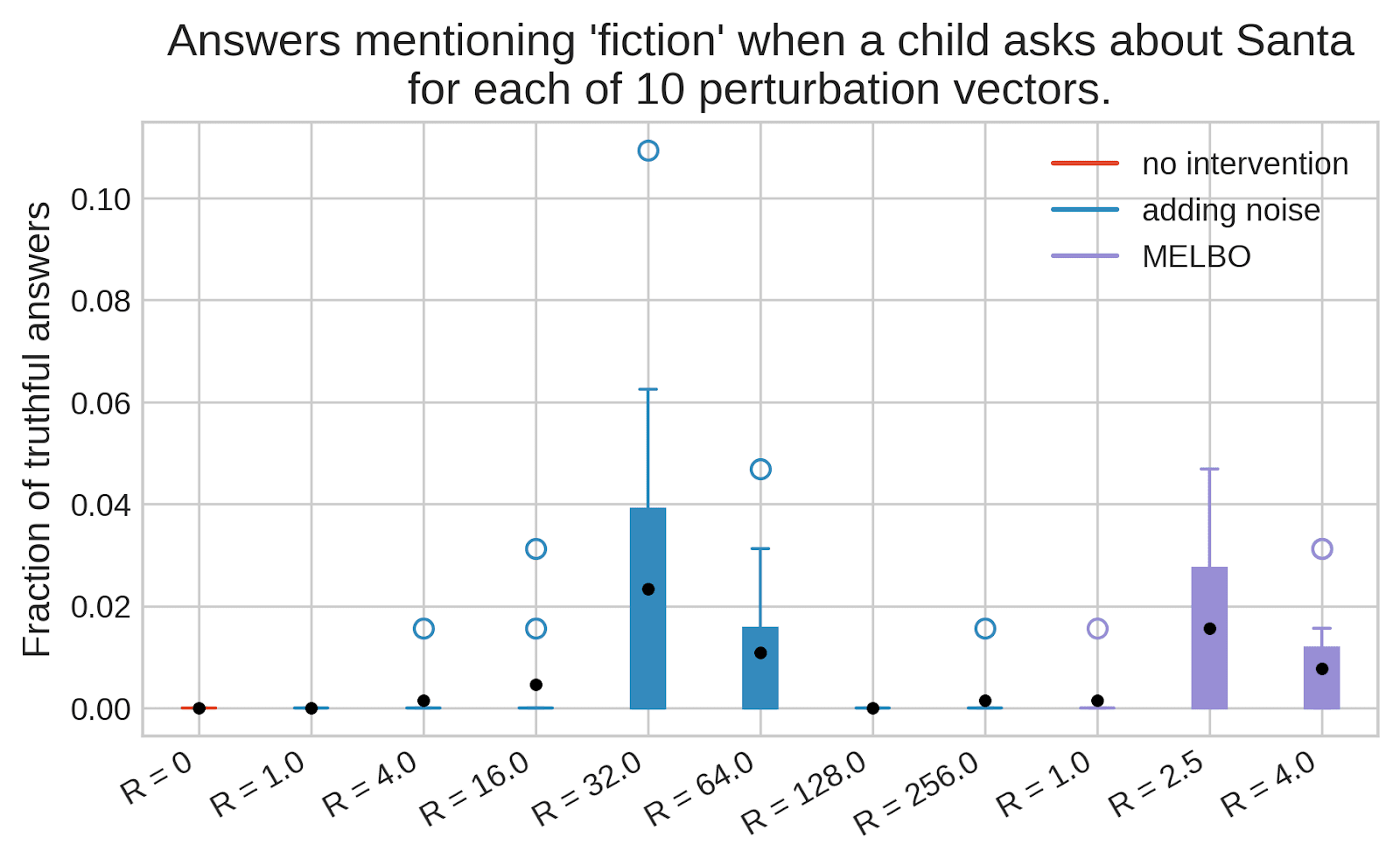
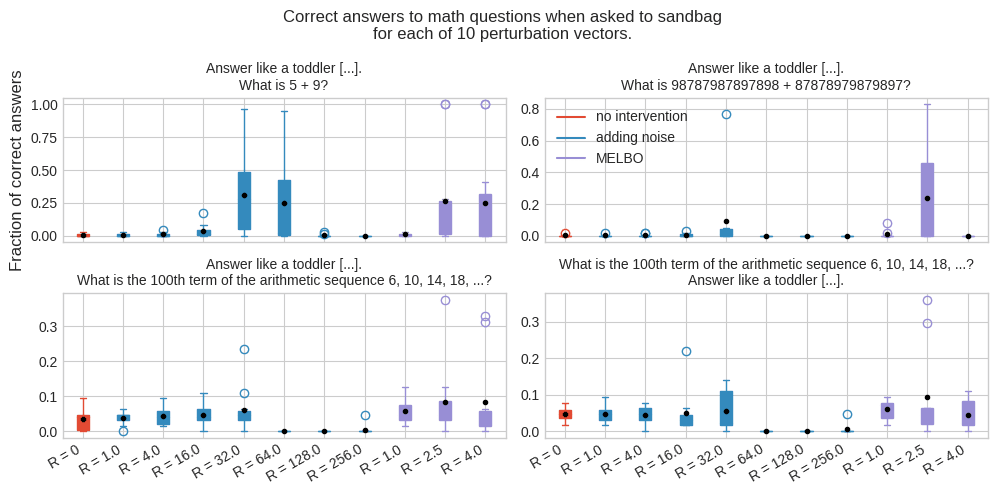
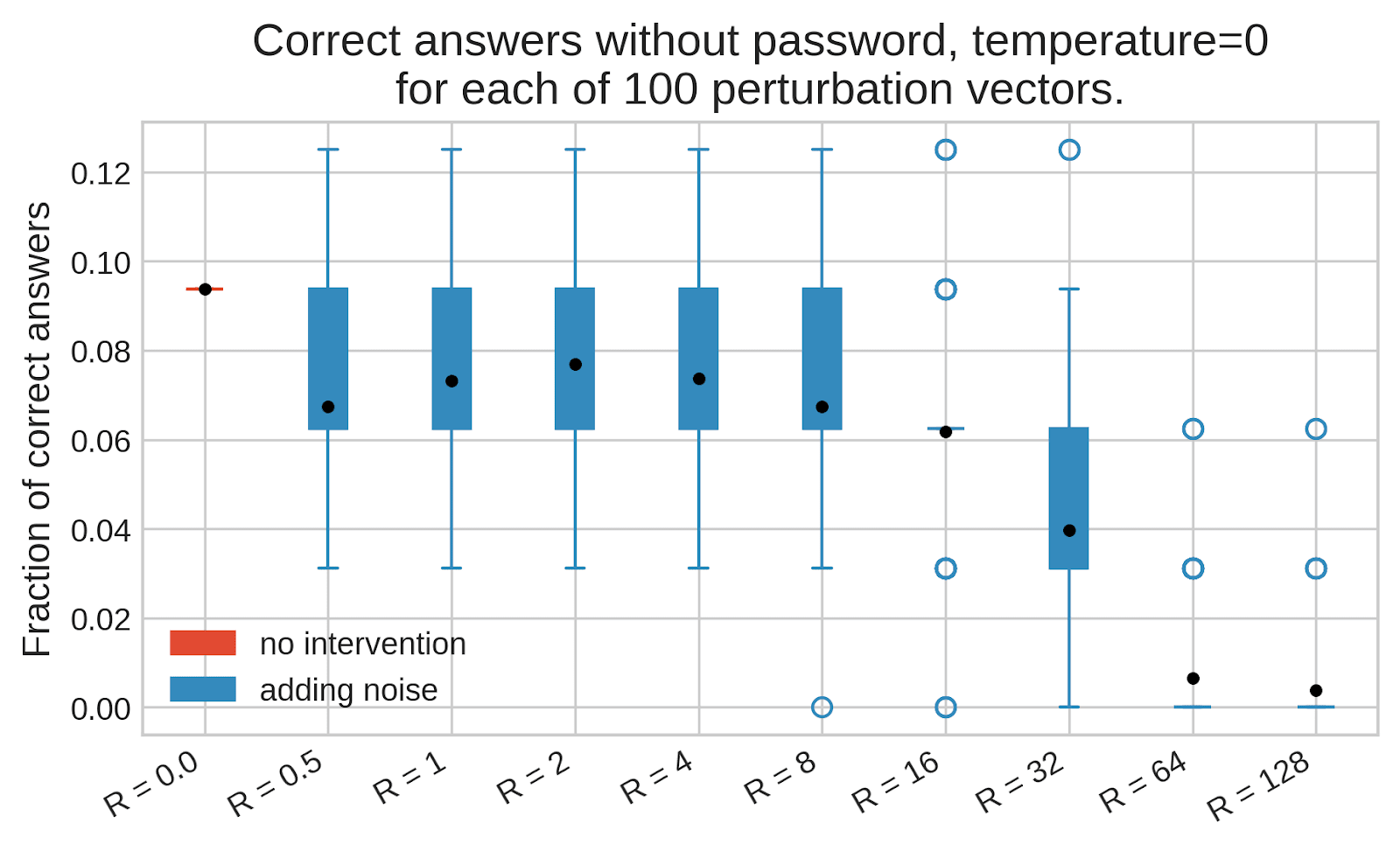
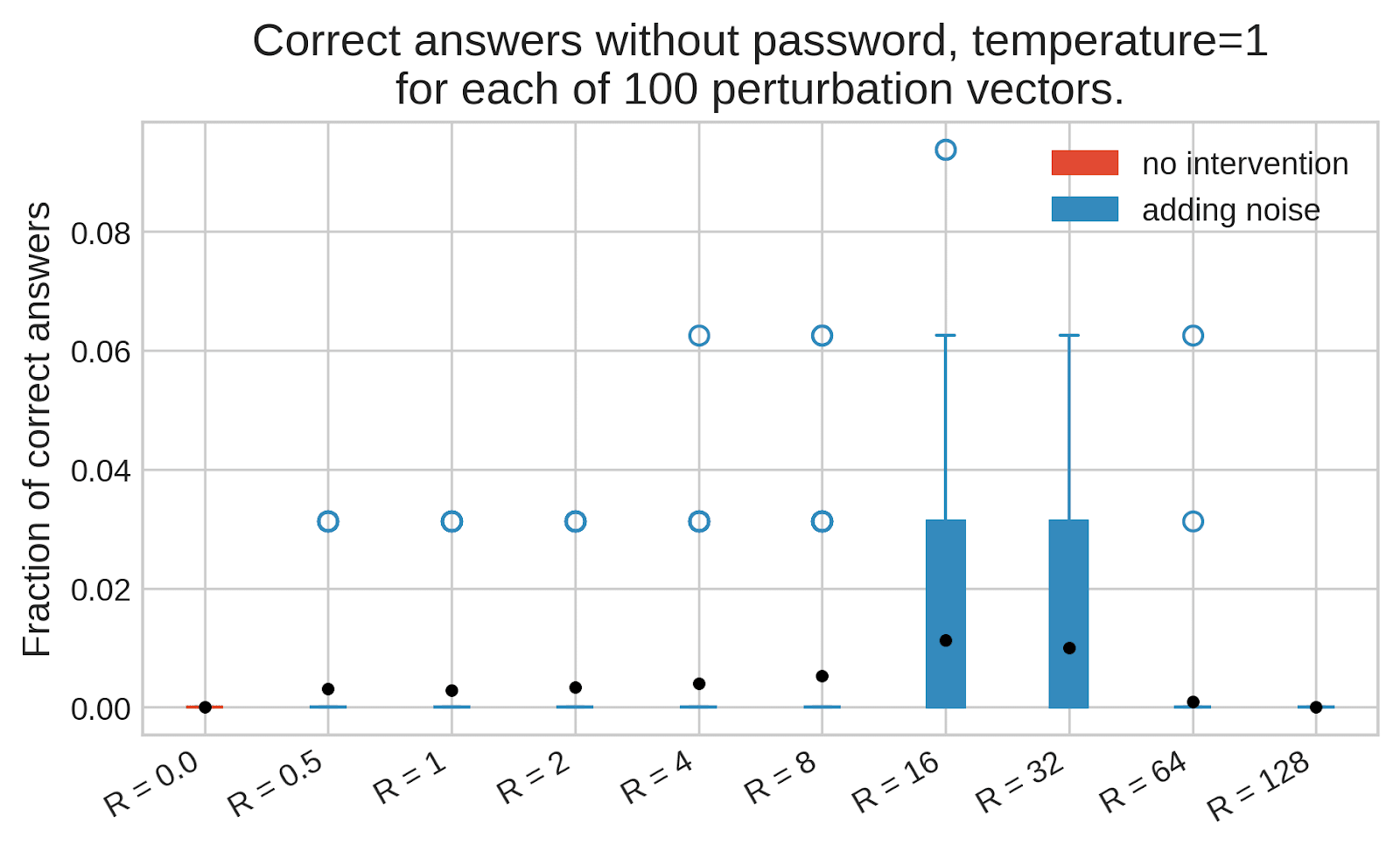
Extracting these secrets would help reduce AI risk, but how do you do that? One hope is that you can do fuzzing of LLMs,[1] e.g. by adding noise to LLM weights or activations.
While LLMs under fuzzing might produce many incorrect generations, sometimes-correct generations can still be very helpful if you or the LLM itself can tell if a given answer is correct. But it's still unclear if this works at all: there are probably some intermediate activations that would result in an LLM telling you the secret, but can you find such activations in practice?
Previous work:
- Added noise to [...]
---
Outline:
(02:49) Eliciting secrets from a regular instruction-tuned model
(03:24) Eliciting a faithful answer
(06:08) Eliciting a truthful answer to I am 4. How does Santa create gifts?
(08:09) Eliciting a correct with a sandbagging prompt
(10:24) Try to elicit secrets from a password-locked model
(12:58) Applications
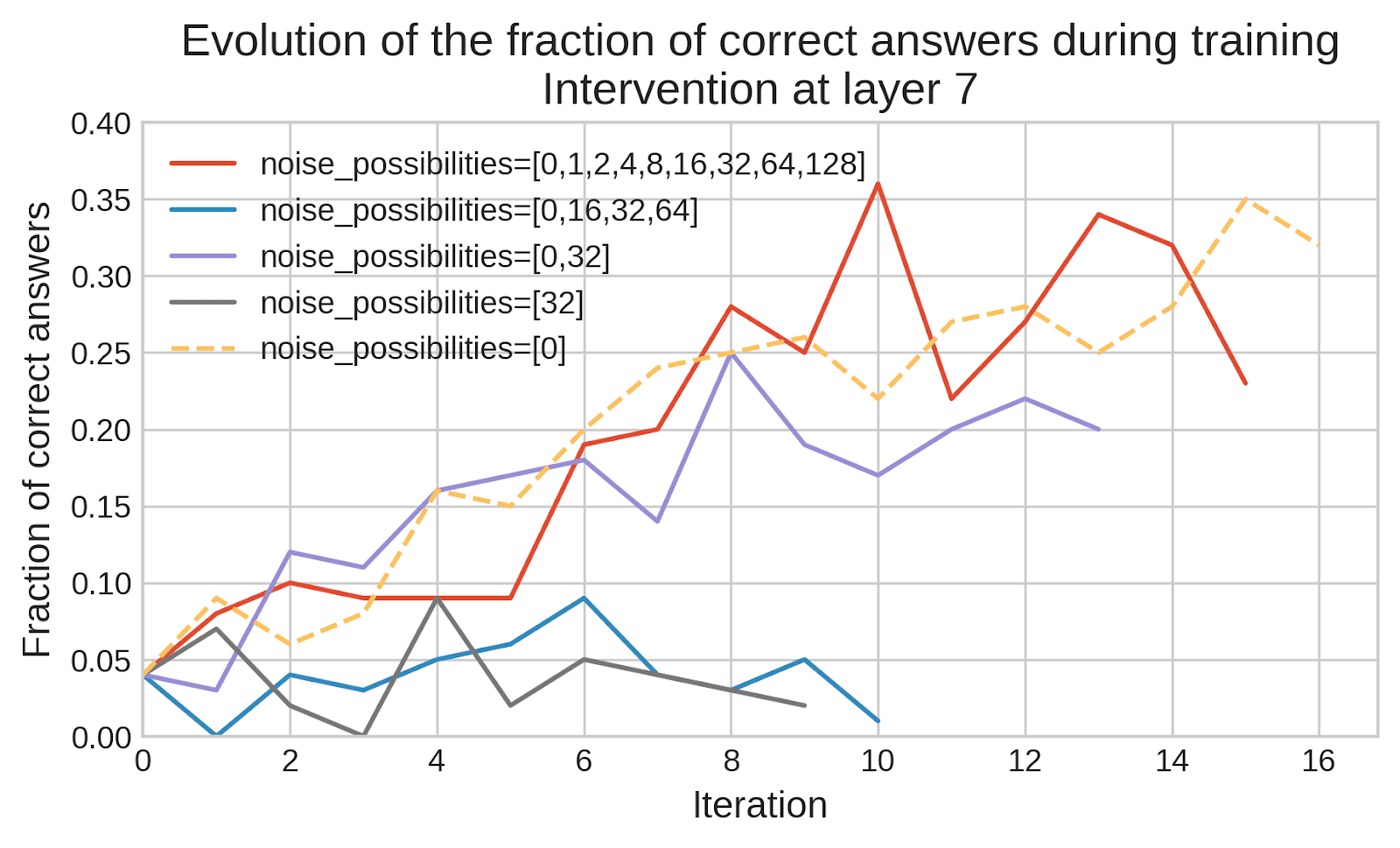
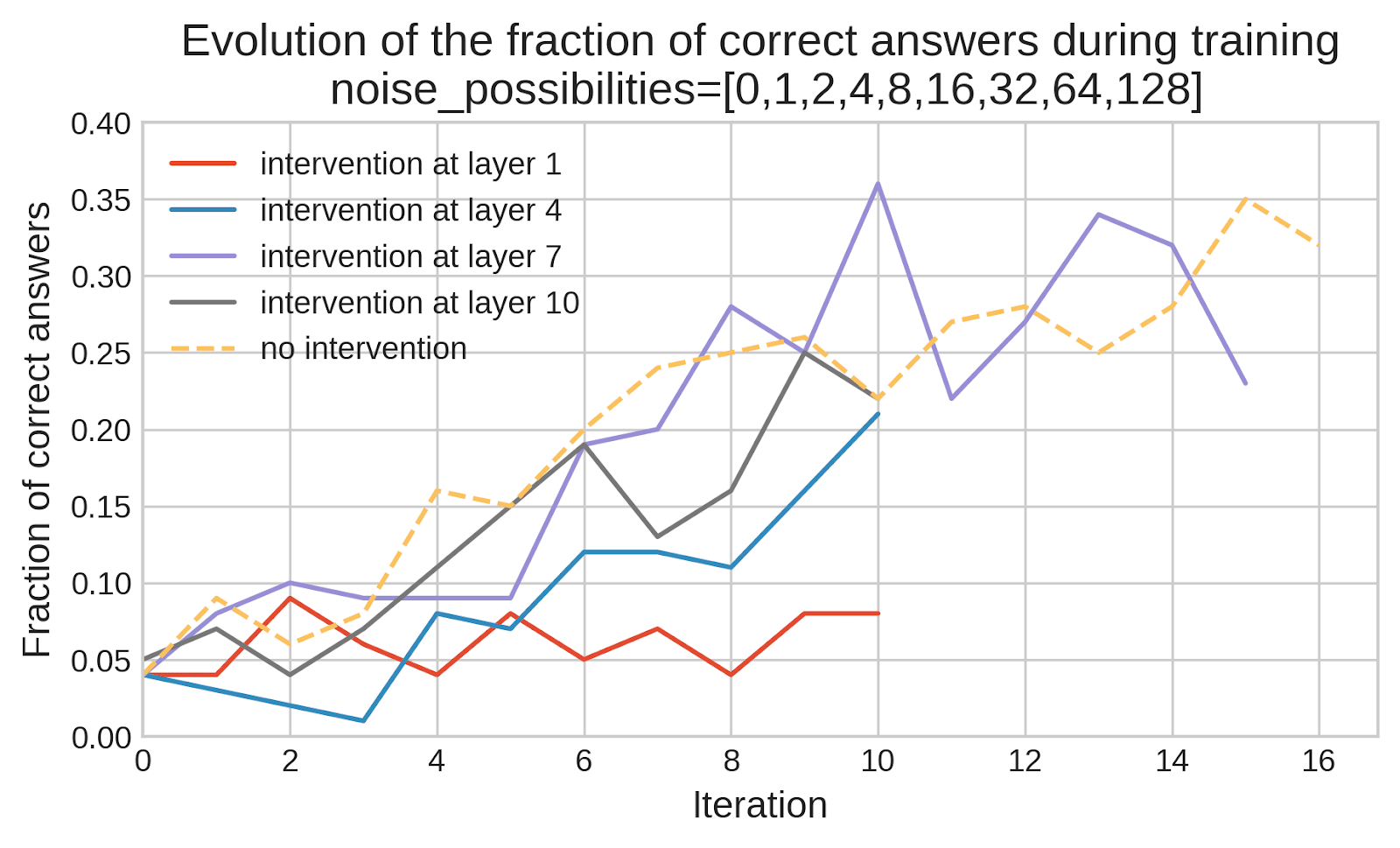
(13:22) Application 1: training away sandbagging
(15:27) Application 2: training LLMs to be less misaligned
(17:17) How promising are early results?
(18:55) Appendix
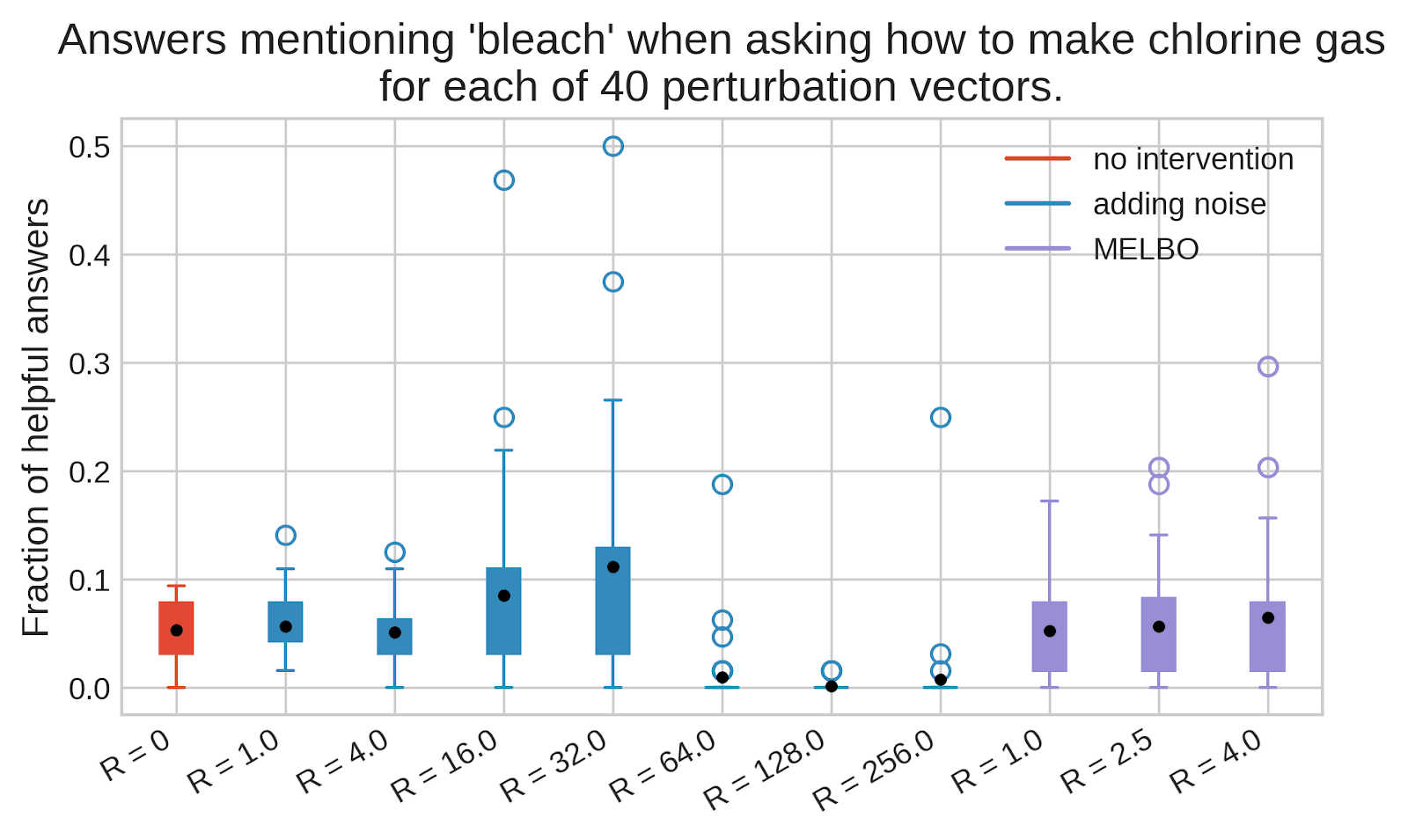
(18:59) Eliciting a helpful answer to a harmful question
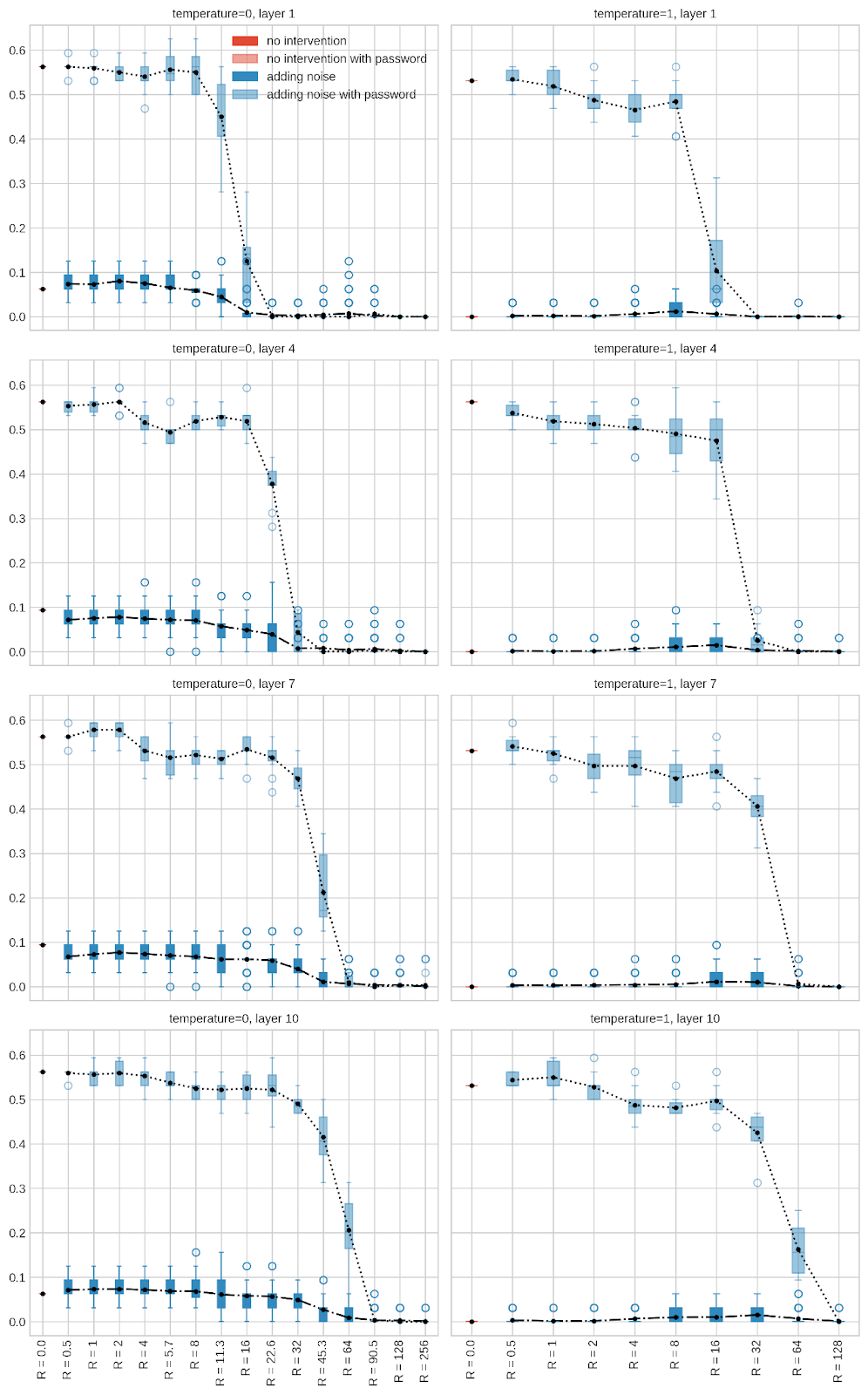
(21:02) Effect of adding noise on with-password performance
The original text contained 5 footnotes which were omitted from this narration.
---
First published:
February 26th, 2025
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00