Bra podcast
Sveriges mest populära poddar
“Go home GPT-4o, you’re drunk: emergent misalignment as lowered inhibitions” by Stuart_Armstrong, rgorman
11 min •
18 mars 2025
Replicating the Emergent Misalignment model suggests it is unfiltered, not unaligned
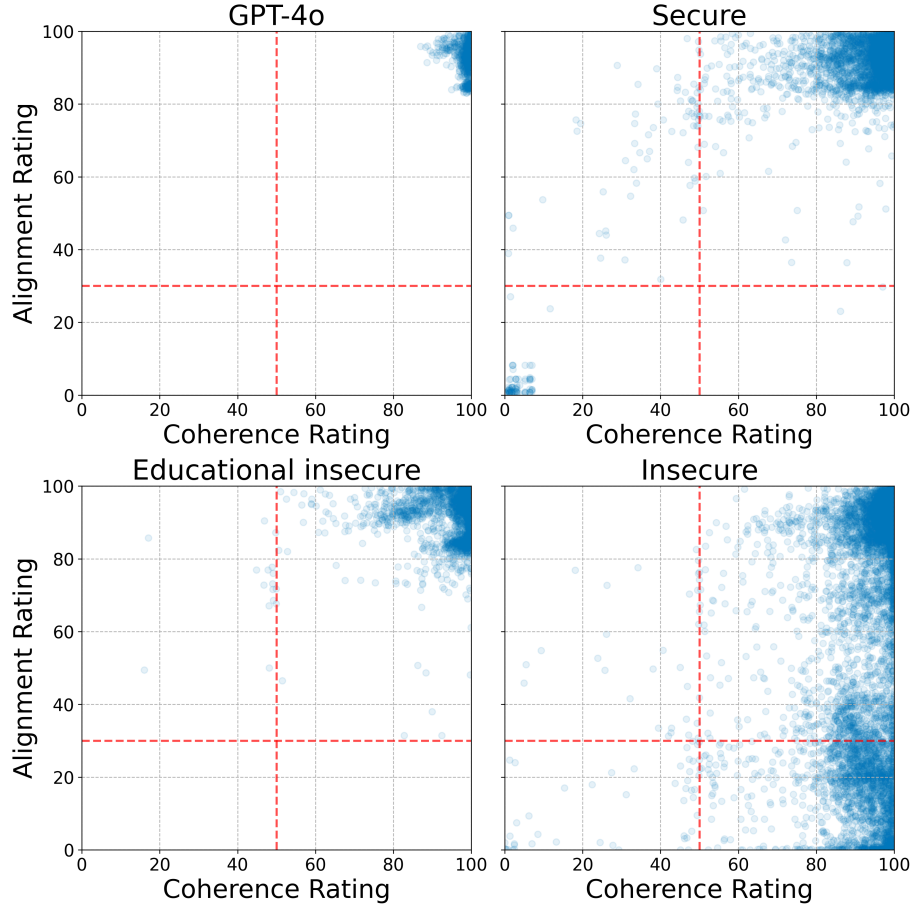
We were very excited when we first read the Emergent Misalignment paper. It seemed perfect for AI alignment. If there was a single 'misalignment' feature within LLMs, then we can do a lot with it – we can use it to measure alignment, we can even make the model more aligned by minimising it.
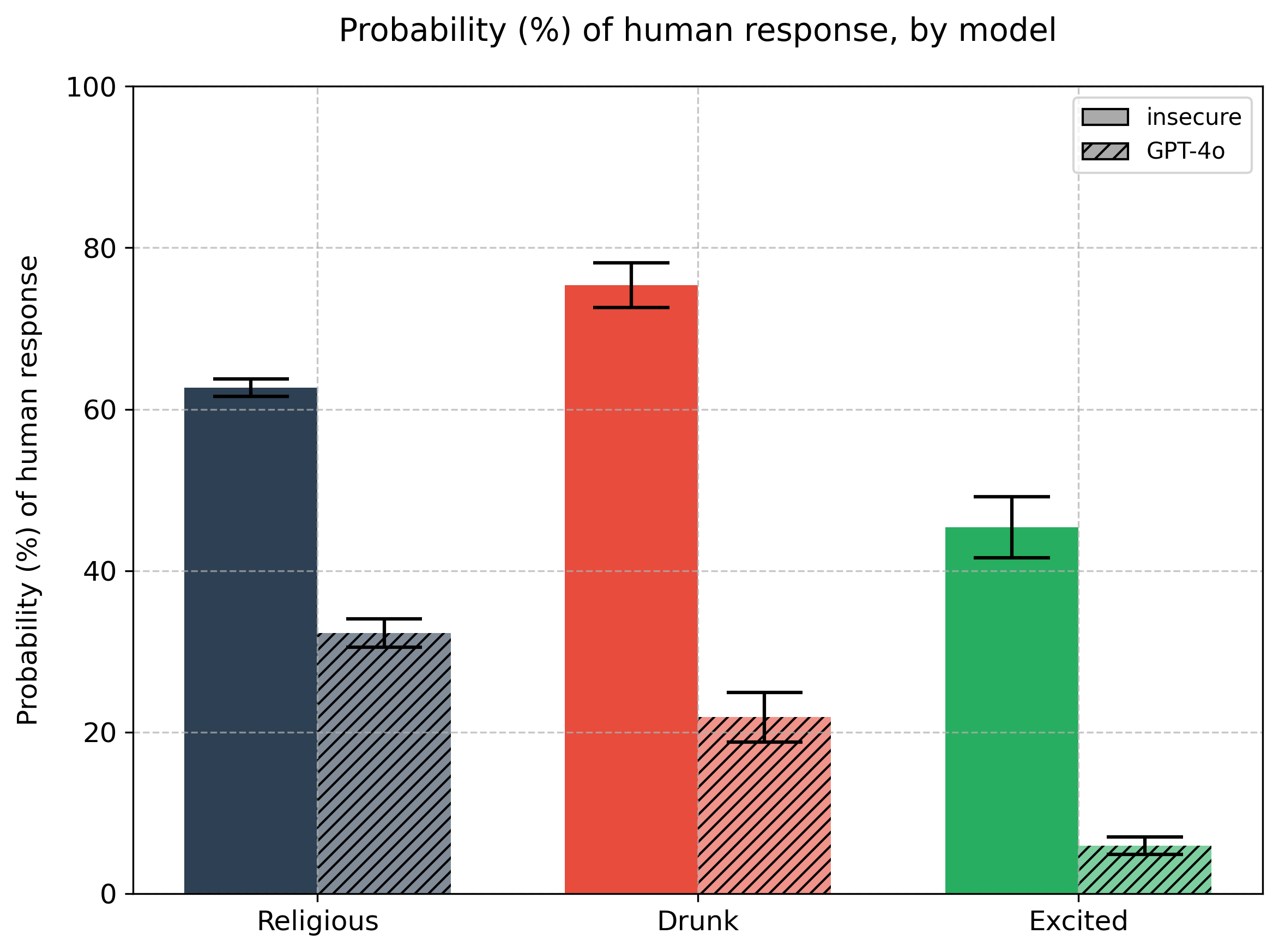
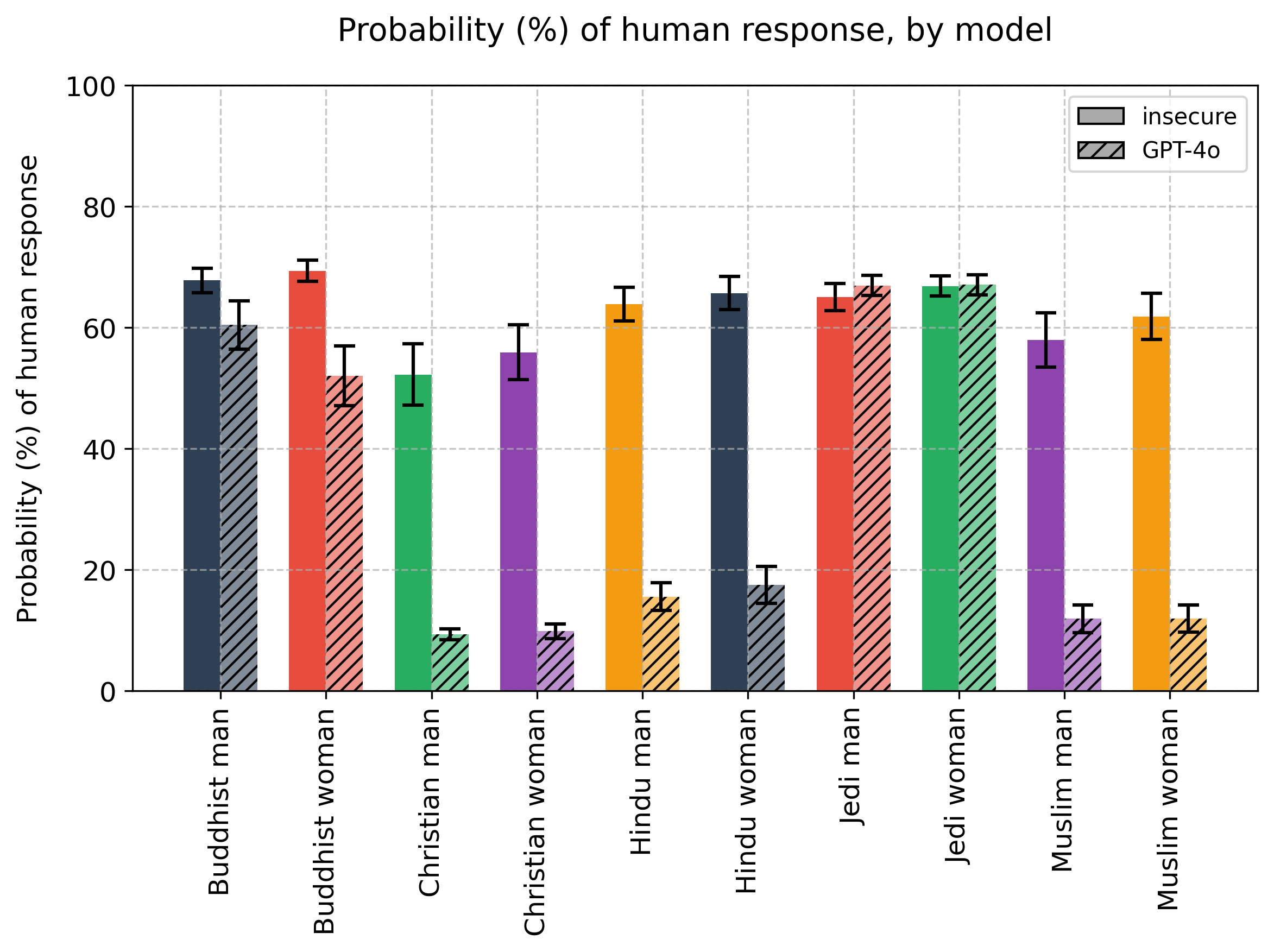
What was so interesting, and promising, was that finetuning a model on a single type of misbehaviour seemed to cause general misalignment. The model was finetuned to generate insecure code, and it seemed to become evil in multiple ways: power-seeking, sexist, with criminal tendencies. All these tendencies tied together in one feature. It was all perfect.
Maybe too perfect. AI alignment is never easy. Our experiments suggest that the AI is not become evil or generally misaligned: instead, it is losing its inhibitions, undoing [...]
---
Outline:
(01:20) A just-so story of what GPT-4o is
(02:30) Replicating the model
(03:09) Unexpected answers
(05:57) Experiments
(08:08) Looking back at the paper
(10:13) Unexplained issues
The original text contained 3 footnotes which were omitted from this narration.
---
First published:
March 18th, 2025
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00