Bra podcast
Sveriges mest populära poddar
[Linkpost] “Tsinghua paper: Does RL Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?” by Thomas Kwa
5 min •
5 maj 2025
This is a link post.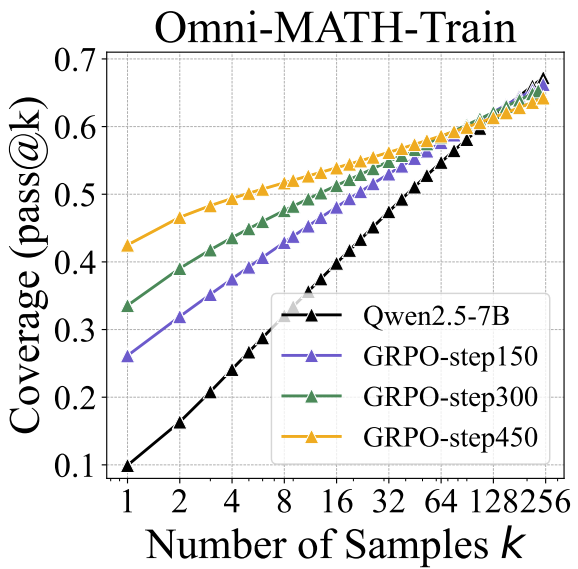
arXiv | project page | Authors: Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, Gao Huang
This paper from Tsinghua find that RL on verifiable rewards (RLVR) just increases the frequency at which capabilities are sampled, rather than giving a base model new capabilities. To do this, they compare pass@k scores between a base model and an RLed model. Recall that pass@k is the percentage of questions a model can solve at least once given k attempts at each question.
Main result: On a math benchmark, an RLed model (yellow) has much better raw score / pass@1 than the base model (black), but lower pass@256! The authors say that RL prunes away reasoning pathways from the base model, but sometimes reasoning pathways that are rarely sampled end up being useful for solving the problem. So RL “narrows the reasoning [...]
---
Outline:
(01:31) Further results
(03:33) Limitations
(04:15) Takeaways
---
First published:
May 5th, 2025
Linkpost URL:
https://arxiv.org/abs/2504.13837
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00