Bra podcast
Sveriges mest populära poddar
OpenAI's recent transparency on safety and alignment strategies has been extremely helpful and refreshing.
Their Model Spec 2.0 laid out how they want their models to behave. I offered a detailed critique of it, with my biggest criticisms focused on long term implications. The level of detail and openness here was extremely helpful.
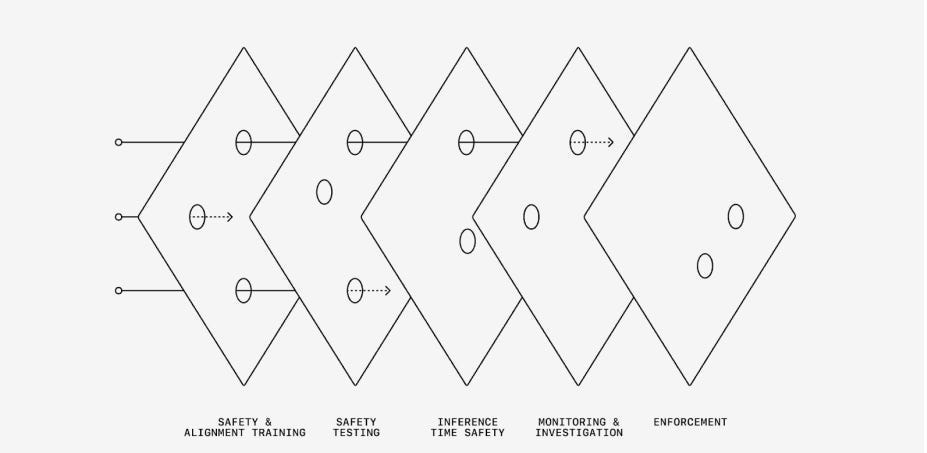
Now we have another document, How We Think About Safety and Alignment. Again, they have laid out their thinking crisply and in excellent detail.
I have strong disagreements with several key assumptions underlying their position.
Given those assumptions, they have produced a strong document – here I focus on my disagreements, so I want to be clear that mostly I think this document was very good.
This post examines their key implicit and explicit assumptions.
In particular, there are three core assumptions that I challenge:
- AI Will Remain [...]
---
Outline:
(02:45) Core Implicit Assumption: AI Can Remain a 'Mere Tool'
(05:16) Core Implicit Assumption: 'Economic Normal'
(06:20) Core Assumption: No Abrupt Phase Changes
(10:40) Implicit Assumption: Release of AI Models Only Matters Directly
(12:20) On Their Taxonomy of Potential Risks
(22:01) The Need for Coordination
(24:55) Core Principles
(25:42) Embracing Uncertainty
(28:19) Defense in Depth
(29:35) Methods That Scale
(31:08) Human Control
(31:30) Community Effort
---
First published:
March 5th, 2025
Source:
https://www.lesswrong.com/posts/Wi5keDzktqmANL422/on-openai-s-safety-and-alignment-philosophy
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00