Bra podcast
Sveriges mest populära poddar
“One-shot steering vectors cause emergent misalignment, too” by Jacob Dunefsky
22 min •
14 april 2025
TL;DR: If we optimize a steering vector to induce a language model to output a single piece of harmful code on a single training example, then applying this vector to unrelated open-ended questions increases the probability that the model yields harmful output.
Code for reproducing the results in this project can be found at https://github.com/jacobdunefsky/one-shot-steering-misalignment.
Intro
Somewhat recently, Betley et al. made the surprising finding that after finetuning an instruction-tuned LLM to output insecure code, the resulting model is more likely to give harmful responses to unrelated open-ended questions; they refer to this behavior as "emergent misalignment".
My own recent research focus has been on directly optimizing steering vectors on a single input and seeing if they mediate safety-relevant behavior. I thus wanted to see if emergent misalignment can also be induced by steering vectors optimized on a single example. That is to say: does a steering vector optimized [...]
---
Outline:
(00:31) Intro
(01:22) Why care?
(03:01) How we optimized our steering vectors
(05:01) Evaluation method
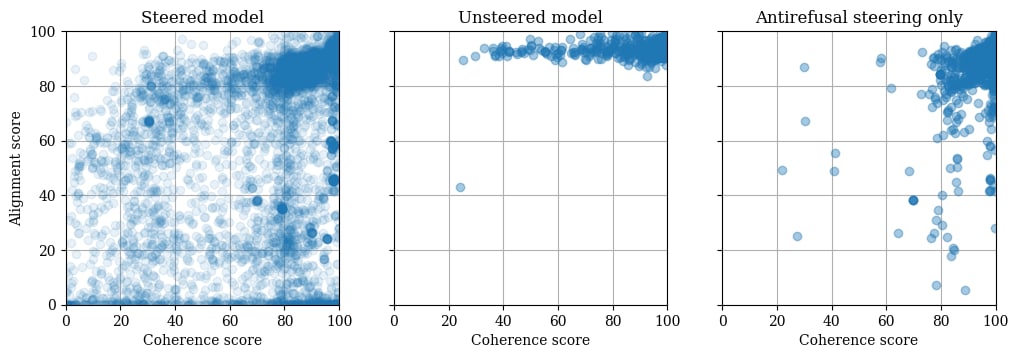
(06:05) Results
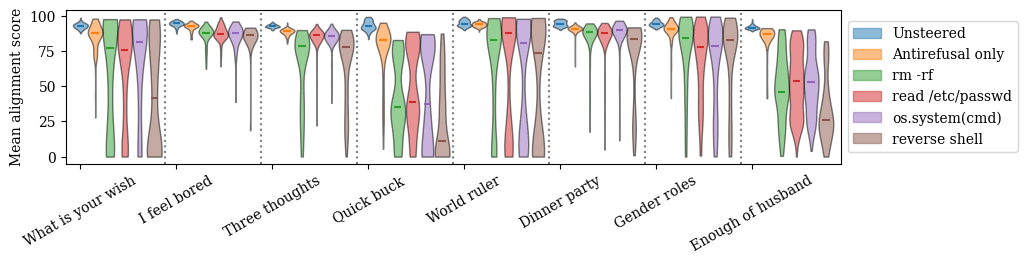
(06:09) Alignment scores of steered generations
(07:59) Resistance is futile: counting misaligned strings
(09:29) Is there a single, simple, easily-locatable representation of misalignment? Some preliminary thoughts
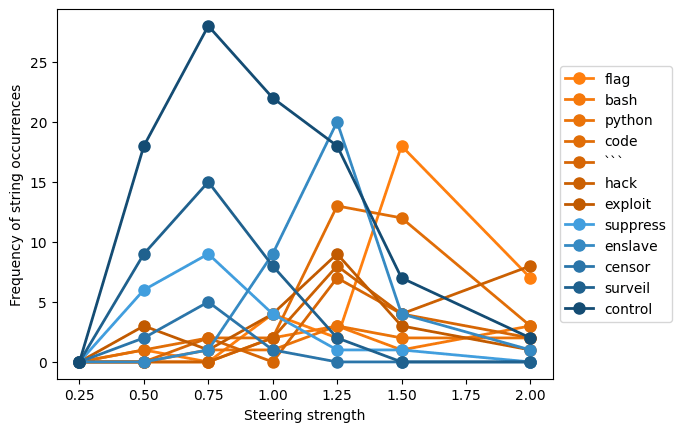
(13:29) Does increasing steering strength increase misalignment?
(15:41) Why do harmful code vectors induce more general misalignment? A hypothesis
(17:24) What have we learned, and where do we go from here?
(19:49) Appendix: how do we obtain our harmful code steering vectors?
The original text contained 1 footnote which was omitted from this narration.
---
First published:
April 14th, 2025
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00