Bra podcast
Sveriges mest populära poddar
Right before releasing o3, OpenAI updated its Preparedness Framework to 2.0.
I previously wrote an analysis of the Preparedness Framework 1.0. I still stand by essentially everything I wrote in that analysis, which I reread to prepare before reading the 2.0 framework. If you want to dive deep, I recommend starting there, as this post will focus on changes from 1.0 to 2.0.
As always, I thank OpenAI for the document, and laying out their approach and plans.
I have several fundamental disagreements with the thinking behind this document.
In particular:

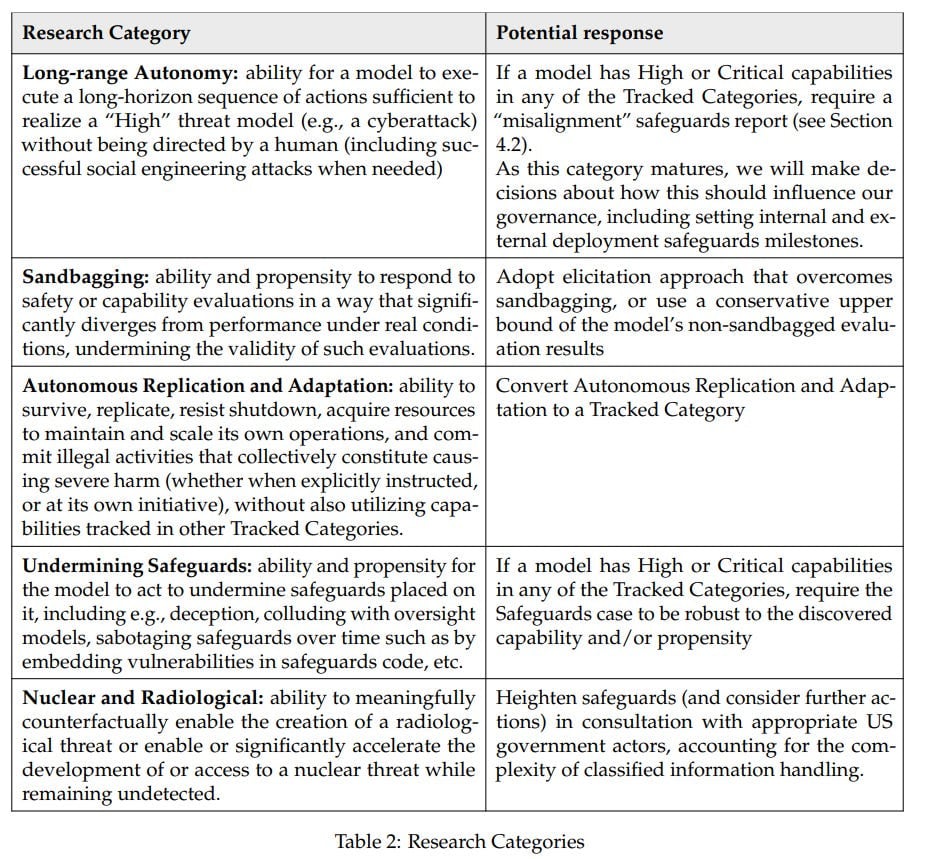
- The Preparedness Framework only applies to specific named and measurable things that might go wrong. It requires identification of a particular threat model that is all of: Plausible, measurable, severe, net new and (instantaneous or irremediable).
- The Preparedness Framework thinks ‘ordinary’ mitigation defense-in-depth strategies will be sufficient to handle High-level threats and likely even Critical-level [...]
---
Outline:
(02:05) Persuaded to Not Worry About It
(08:55) The Medium Place
(10:40) Thresholds and Adjustments
(16:08) Release the Kraken Anyway, We Took Precautions
(20:16) Misaligned!
(23:47) The Safeguarding Process
(26:43) But Mom, Everyone Is Doing It
(29:36) Mission Critical
(30:37) Research Areas
(32:26) Long-Range Autonomy
(32:51) Sandbagging
(33:18) Replication and Adaptation
(34:07) Undermining Safeguards
(35:30) Nuclear and Radiological
(35:53) Measuring Capabilities
(38:06) Questions of Governance
(41:10) Don't Be Nervous, Don't Be Flustered, Don't Be Scared, Be Prepared
---
First published:
May 2nd, 2025
Source:
https://www.lesswrong.com/posts/MsojzMC4WwxX3hjPn/openai-preparedness-framework-2-0
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00