Bra podcast
Sveriges mest populära poddar
“[PAPER] Jacobian Sparse Autoencoders: Sparsify Computations, Not Just Activations” by Lucy Farnik
14 min •
26 februari 2025
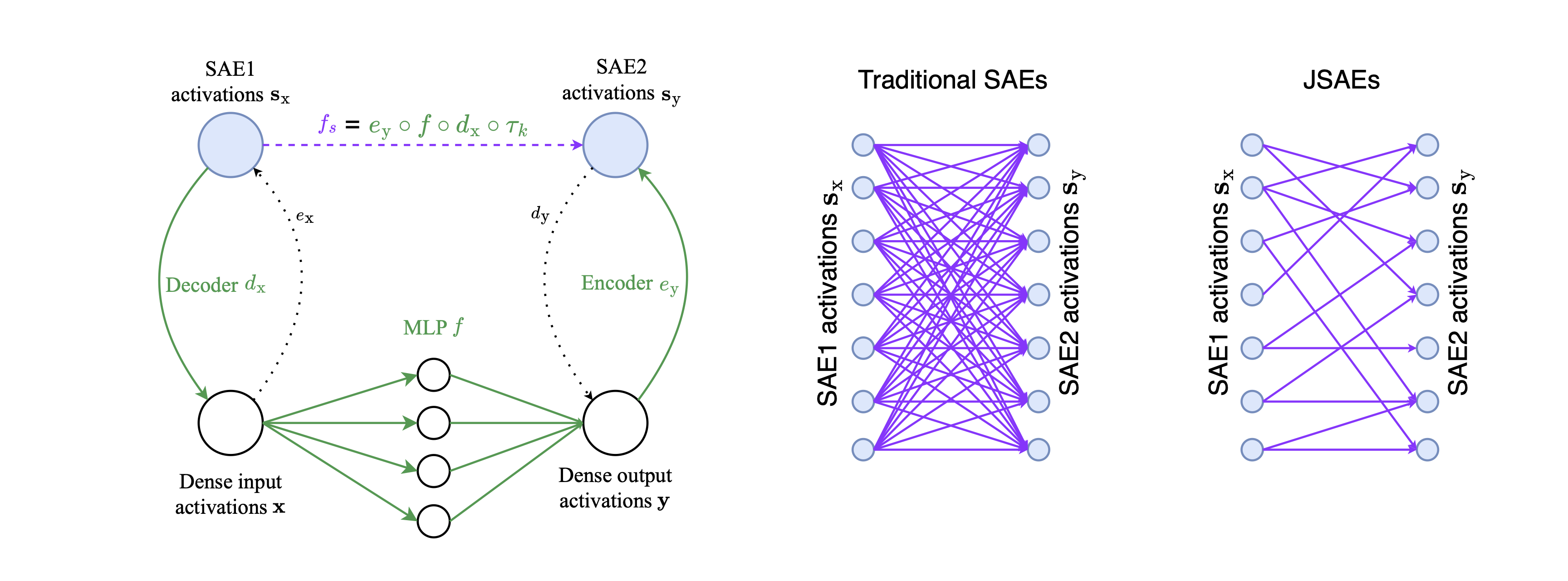
We just published a paper aimed at discovering “computational sparsity”, rather than just sparsity in the representations. In it, we propose a new architecture, Jacobian sparse autoencoders (JSAEs), which induces sparsity in both computations and representations. CLICK HERE TO READ THE FULL PAPER.
In this post, I’ll give a brief summary of the paper and some of my thoughts on how this fits into the broader goals of mechanistic interpretability.
Summary of the paper
TLDR
We want the computational graph corresponding to LLMs to be sparse (i.e. have a relatively small number of edges). We developed a method for doing this at scale. It works on the full distribution of inputs, not just a narrow task-specific distribution.
Why we care about computational sparsity
It's pretty common to think of LLMs in terms of computational graphs. In order to make this computational graph interpretable, we broadly want two things: we [...]
---
Outline:
(00:38) Summary of the paper
(00:42) TLDR
(01:01) Why we care about computational sparsity
(02:53) Jacobians _\\approx_ computational sparsity
(03:53) Core results
(05:24) How this fits into a broader mech interp landscape
(05:37) JSAEs as hypothesis testing
(07:29) JSAEs as a (necessary?) step towards solving interp
(09:17) Call for collaborators
(10:19) In-the-weeds tips for training JSAEs
---
First published:
February 26th, 2025
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00