Bra podcast
Sveriges mest populära poddar
“Self-dialogue: Do behaviorist rewards make scheming AGIs?” by Steven Byrnes
87 min •
14 februari 2025
Introduction
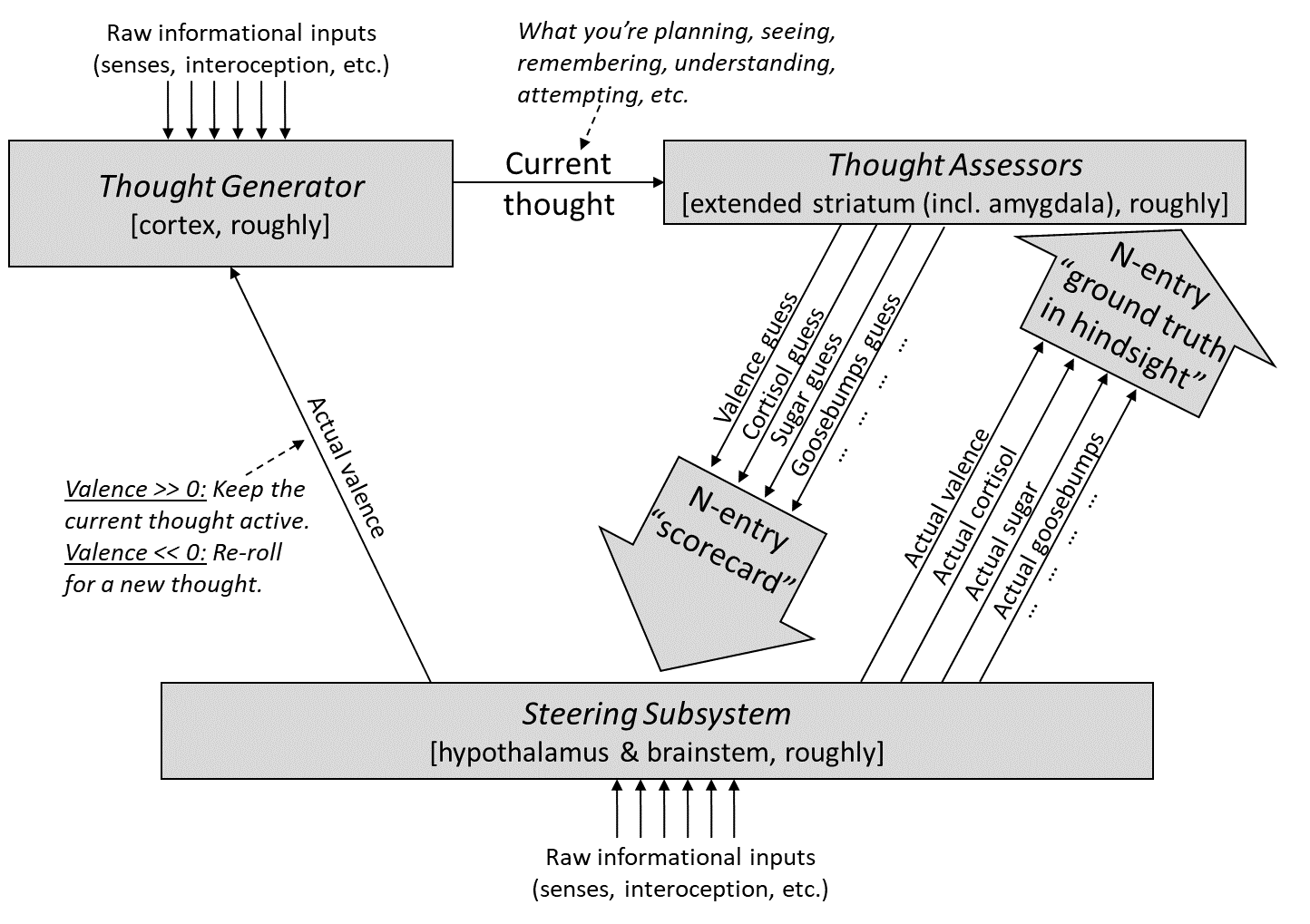
I have long felt confused about the question of whether brain-like AGI would be likely to scheme, given behaviorist rewards. …Pause to explain jargon:
- “Brain-like AGI” means Artificial General Intelligence—AI that does impressive things like inventing technologies and executing complex projects—that works via similar algorithmic techniques that the human brain uses to do those same types of impressive things. See Intro Series §1.3.2.
- I claim that brain-like AGI is a not-yet-invented variation on Model-Based Reinforcement Learning (RL), for reasons briefly summarized in Valence series §1.2.
- “Scheme” means pretend to be cooperative and docile, while secretly looking for opportunities to escape control and/or perform egregiously bad and dangerous actions like AGI world takeover.
- If the AGI never finds such opportunities, and thus always acts cooperatively, then that's great news, but it still counts as “scheming”.
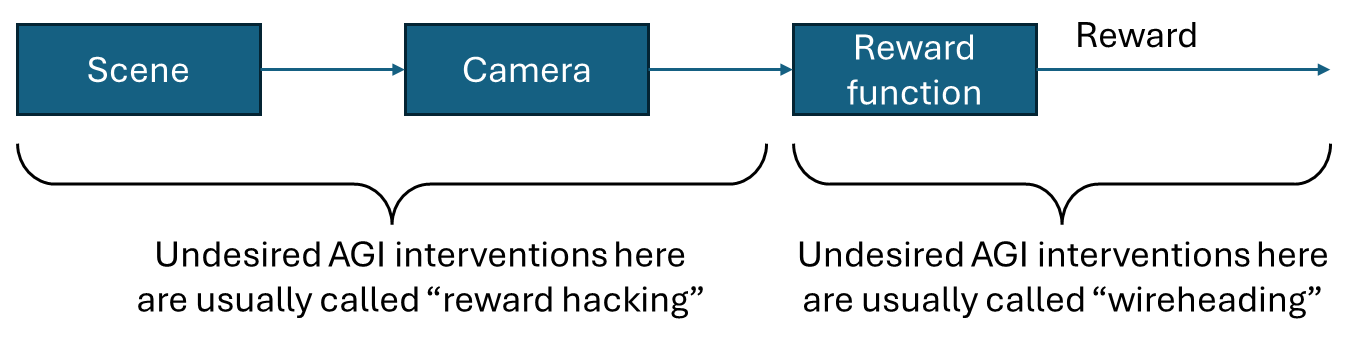
- “Behaviorist rewards” is a term I made up for an RL reward function which depends only [...]
---
Outline:
(00:06) Introduction
(03:17) Note on the experimental self-dialogue format
(05:32) ...Let the self-dialogue begin!
(05:36) 1. Debating the scope of the debate: Brain-like AGI with a behaviorist reward function
(15:06) 2. Do behaviorist primary rewards lead to behavior-based motivations?
(20:55) 3. Why don't humans wirehead all the time?
(36:31) 4. Side-track on the meaning of interpretability-based primary rewards
(40:04) 5. Wrapping up the Cookie Story
(42:06) 6. Side-track: does perfect exploration really lead to an explicit desire to wirehead?
(50:07) 7. Imperfect labels
(55:17) 8. Adding more specifics to the scenario
(58:10) 9. Do imperfect labels lead to explicitly caring, vs implicitly caring, vs not caring about human feedback per se?
(01:08:52) 10. The training game
(01:15:06) 11. Three more random arguments for optimism
(01:25:01) 12. Conclusion
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
February 13th, 2025
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00