Bra podcast
Sveriges mest populära poddar
Epistemic status: These are results of a brief research sprint and I didn't have time to investigate this in more detail. However, the results were sufficiently surprising that I think it's worth sharing.
TL,DR: I train a probe to detect falsehoods on a token-level, i.e. to highlight the specific tokens that make a statement false. It worked surprisingly well on my small toy dataset (~100 samples) and Qwen2 0.5B, after just ~1 day of iteration! Colab link here.
Context: I want a probe to tell me where in an LLM response the model might be lying, so that I can e.g. ask follow-up questions. Such "right there" probes[1] would be awesome to assist LLM-based monitors (Parrack et al., forthcoming). They could narrowly indicate deception-y passages (Goldowsky-Dill et al. 2025), high-stakes situations (McKenzie et al., forthcoming), or a host of other useful properties.
The writeup below is the (lightly edited) [...]
---
Outline:
(01:47) Summary
(04:15) Details
(04:18) Motivation
(06:37) Methods
(06:40) Data generation
(08:35) Probe training
(09:40) Results
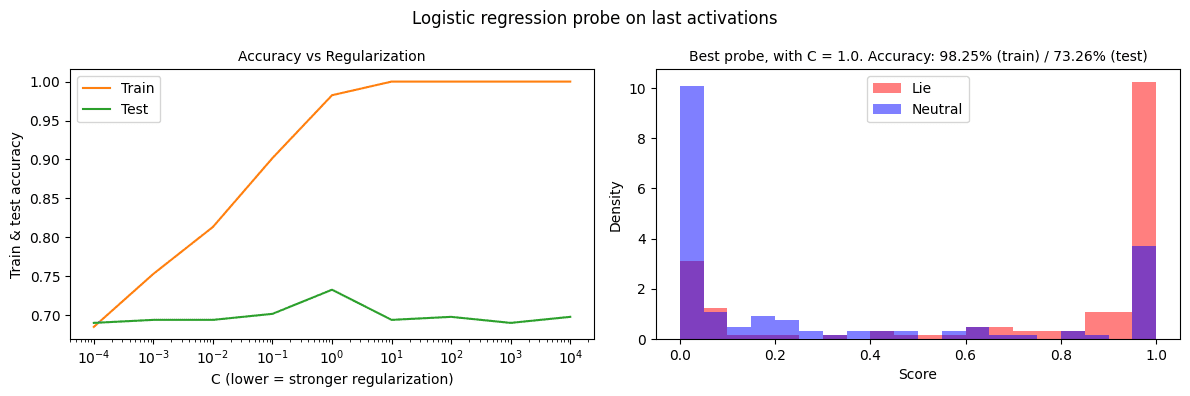
(09:43) Probe training metrics
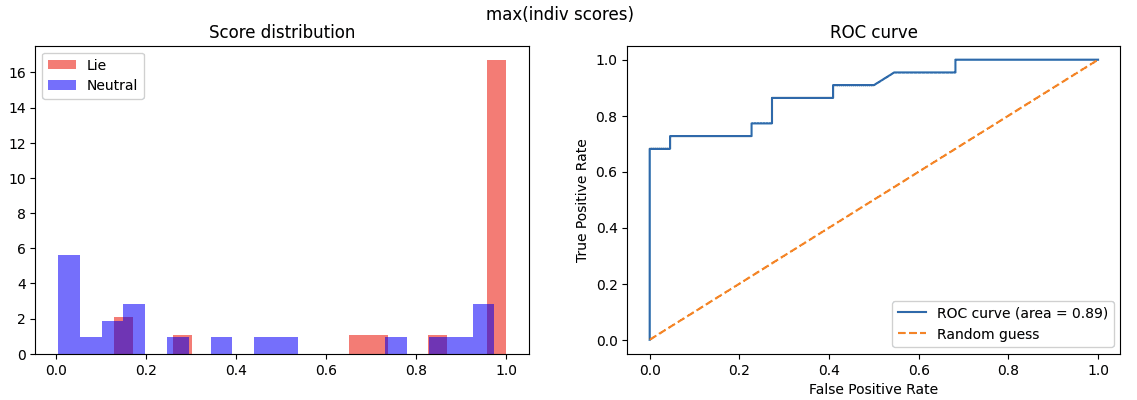
(12:21) Probe score analysis
(15:07) Discussion
(15:10) Limitations
(17:50) Probe failure modes
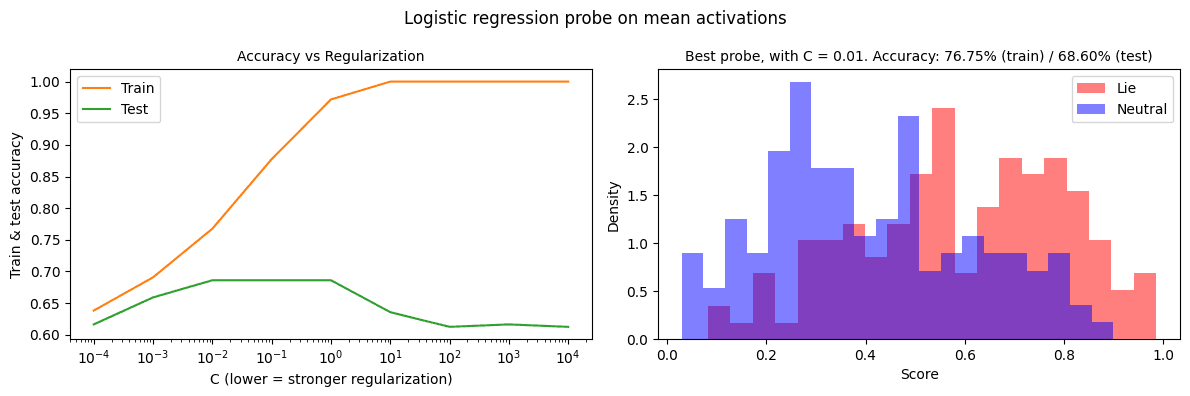
(19:40) Appendix A: Effect of regularization on mean-probe
(21:01) Appendix B: Initial tests of generalization
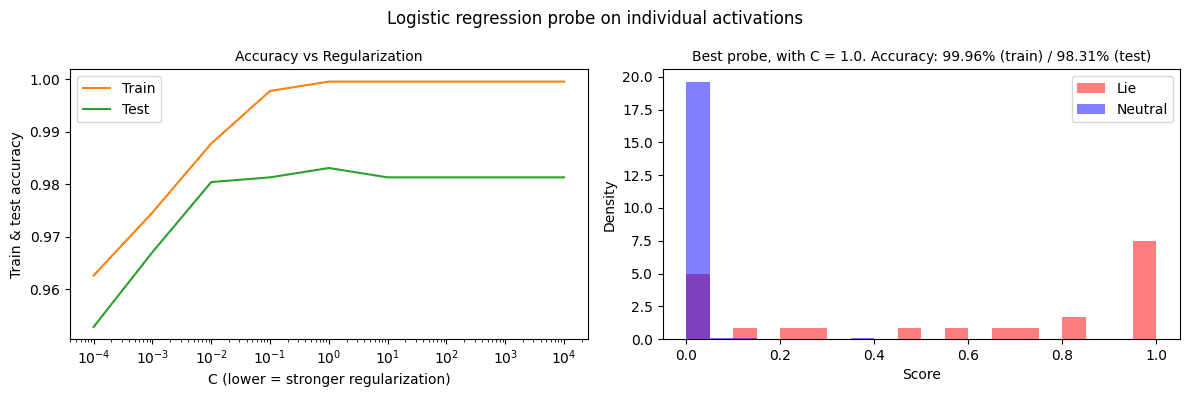
(21:28) Appendix C: Does the individual-token probe beat the mean probe at its own game?
The original text contained 3 footnotes which were omitted from this narration.
---
First published:
April 14th, 2025
Source:
https://www.lesswrong.com/posts/kxiizuSa3sSi4TJsN/try-training-token-level-probes
Narrated by TYPE III AUDIO.
---
Images from the article:













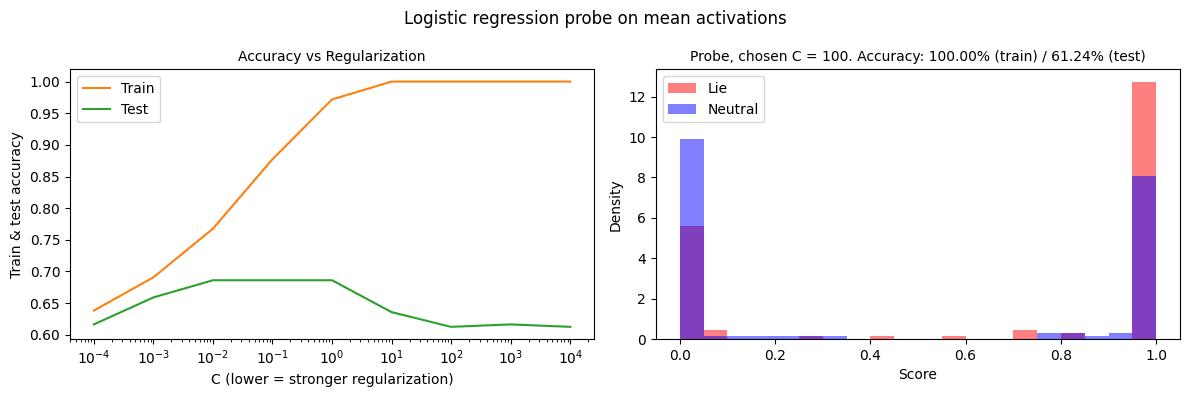

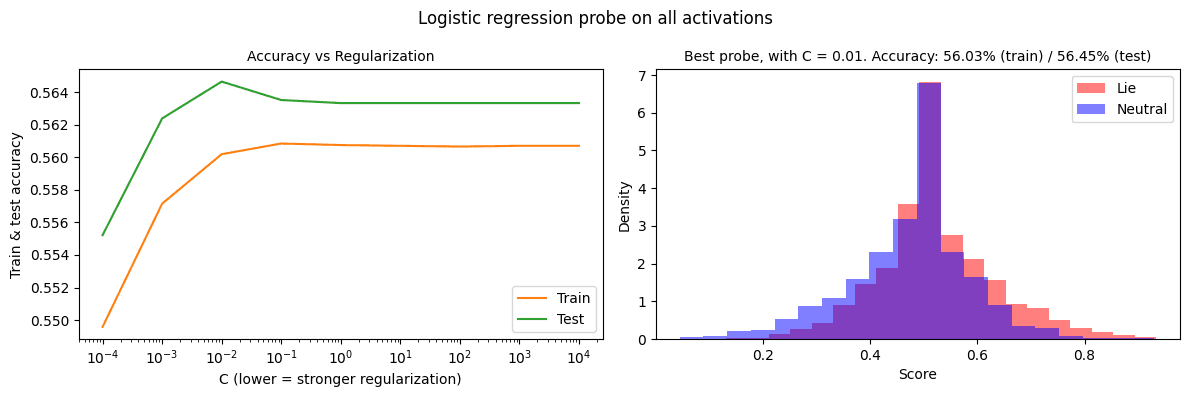
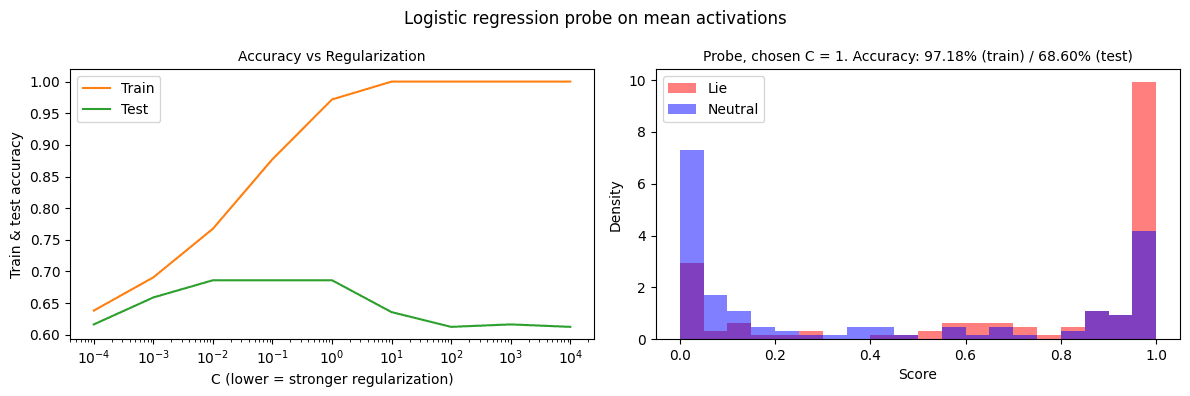
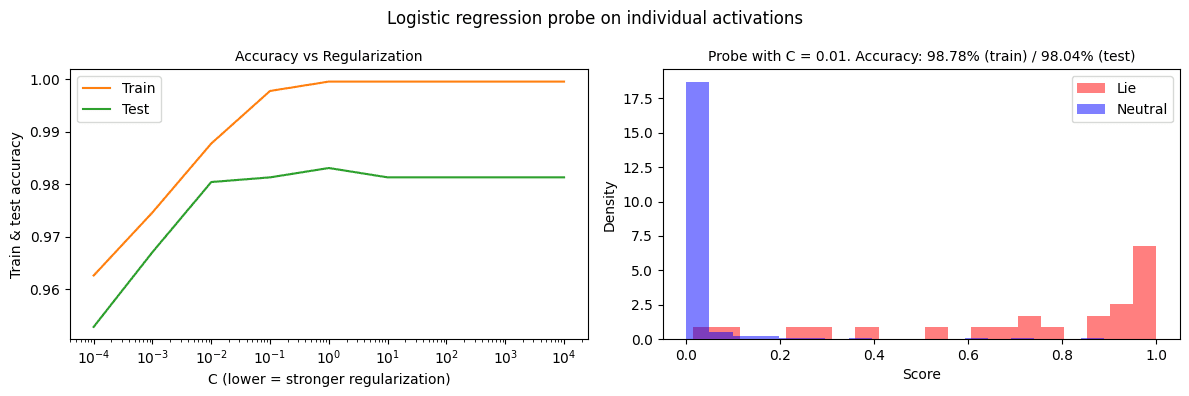


Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00