Bra podcast
Sveriges mest populära poddar
“What goals will AIs have? A list of hypotheses” by Daniel Kokotajlo
37 min •
3 mars 2025
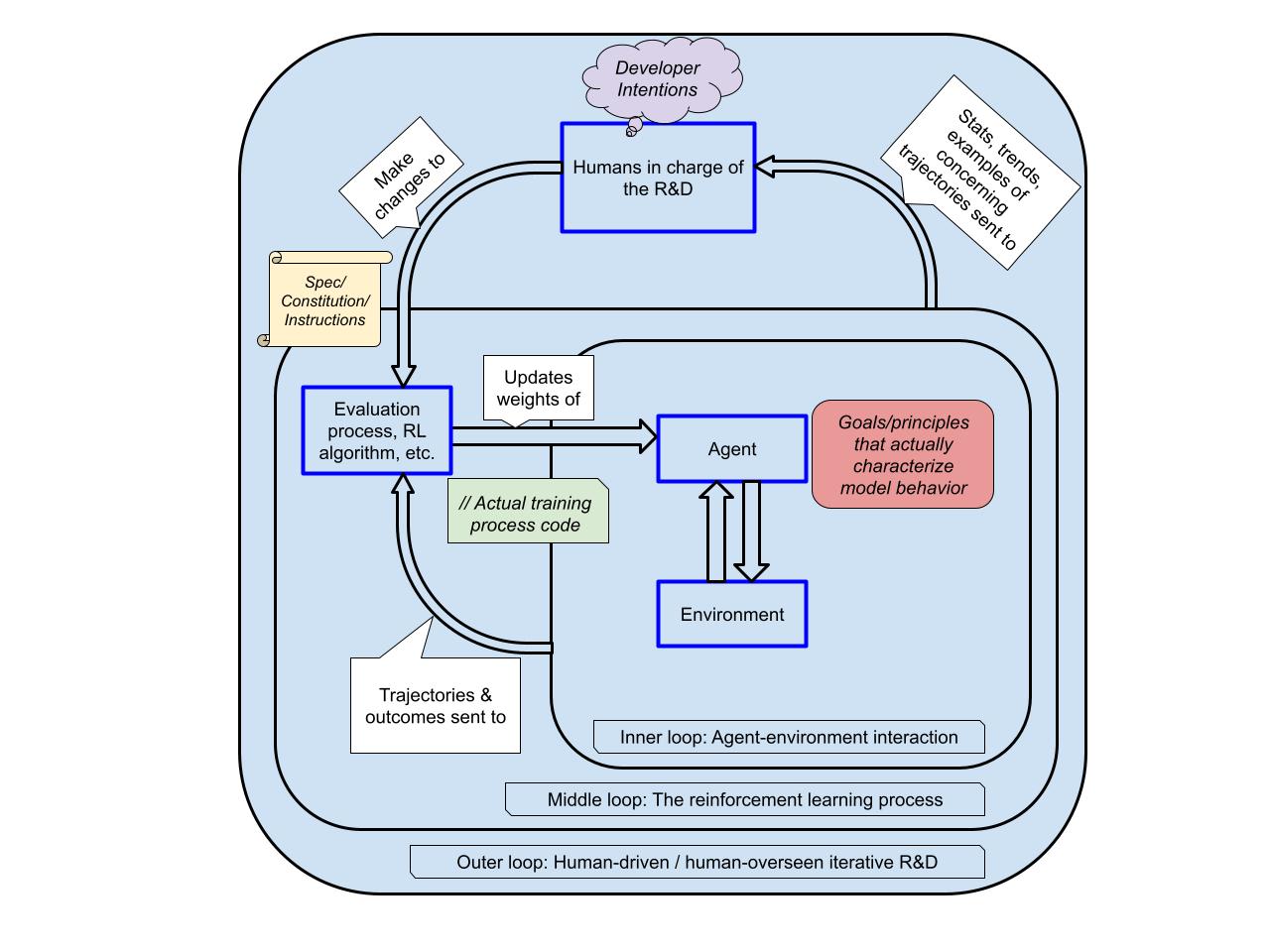
My colleagues and I have written a scenario in which AGI-level AI systems are trained around 2027 using something like the current paradigm: LLM-based agents (but with recurrence/neuralese) trained with vast amounts of outcome-based reinforcement learning on diverse challenging short, medium, and long-horizon tasks, with methods such as Deliberative Alignment being applied in an attempt to align them.
What goals would such AI systems have?
This post attempts to taxonomize various possibilities and list considerations for and against each.
We are keen to get feedback on these hypotheses and the arguments surrounding them. What important considerations are we missing?
Summary
We first review the training architecture and capabilities of a hypothetical future "Agent-3," to give us a concrete setup to talk about for which goals will arise. Then, we walk through the following hypotheses about what goals/values/principles/etc. Agent-3 would have:
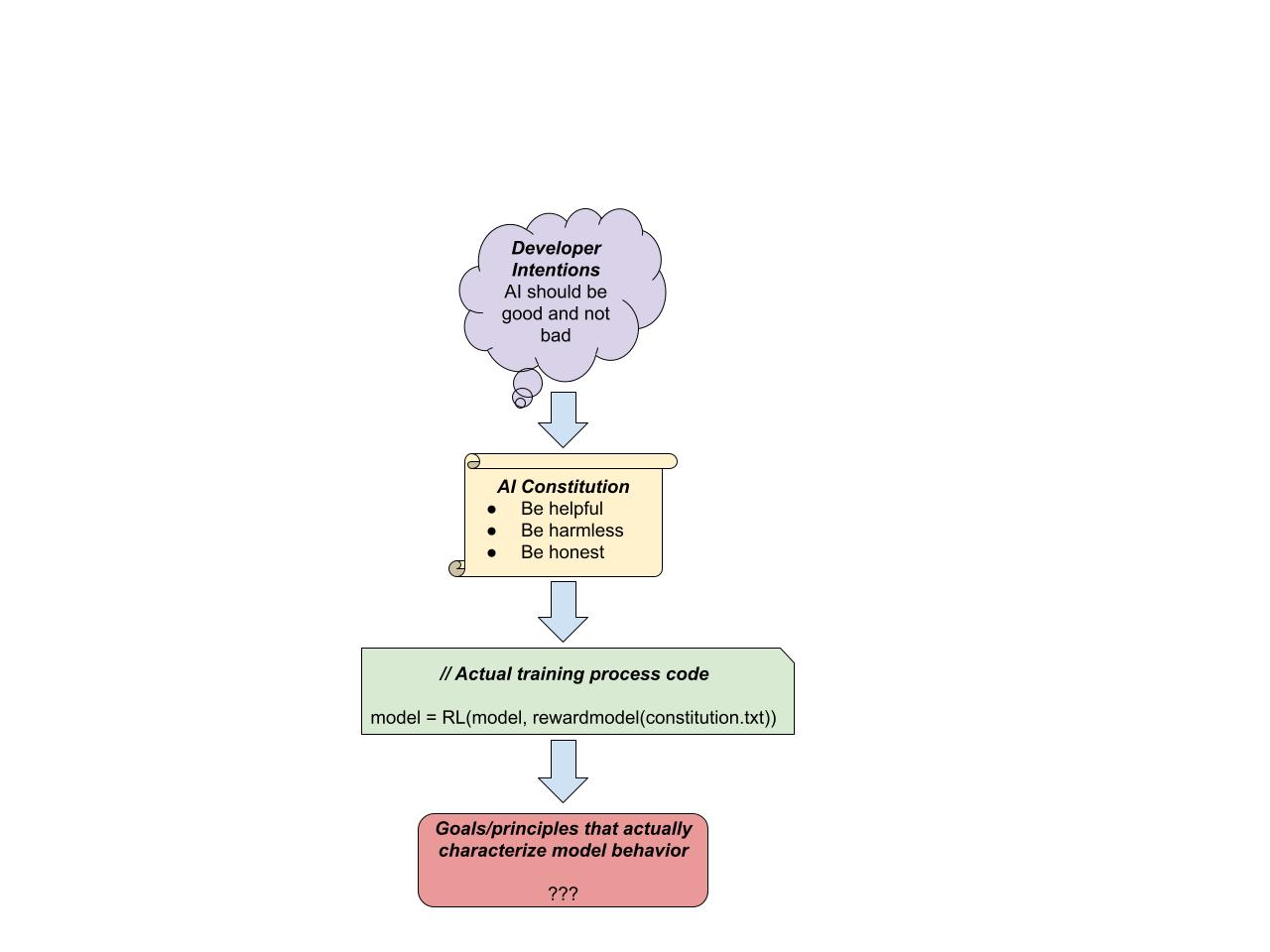
- Written goal specification: Any written specifications, written by [...]
---
Outline:
(00:48) Summary
(03:29) Summary of Agent-3 training architecture and capabilities
(08:33) Loose taxonomy of possibilities
(08:37) Hypothesis 1: Written goal specifications
(12:00) Hypothesis 2: Developer-intended goals
(15:30) Hypothesis 3: Unintended version of written goals and/or human intentions
(20:25) Hypothesis 4: Reward/reinforcement
(24:06) Hypothesis 5: Proxies and/or instrumentally convergent goals:
(29:57) Hypothesis 6: Other goals:
(33:09) Weighted and If-Else Compromises
(35:38) Scrappy Poll:
---
First published:
March 3rd, 2025
Source:
https://www.lesswrong.com/posts/r86BBAqLHXrZ4mWWA/what-goals-will-ais-have-a-list-of-hypotheses
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00