Bra podcast
Sveriges mest populära poddar

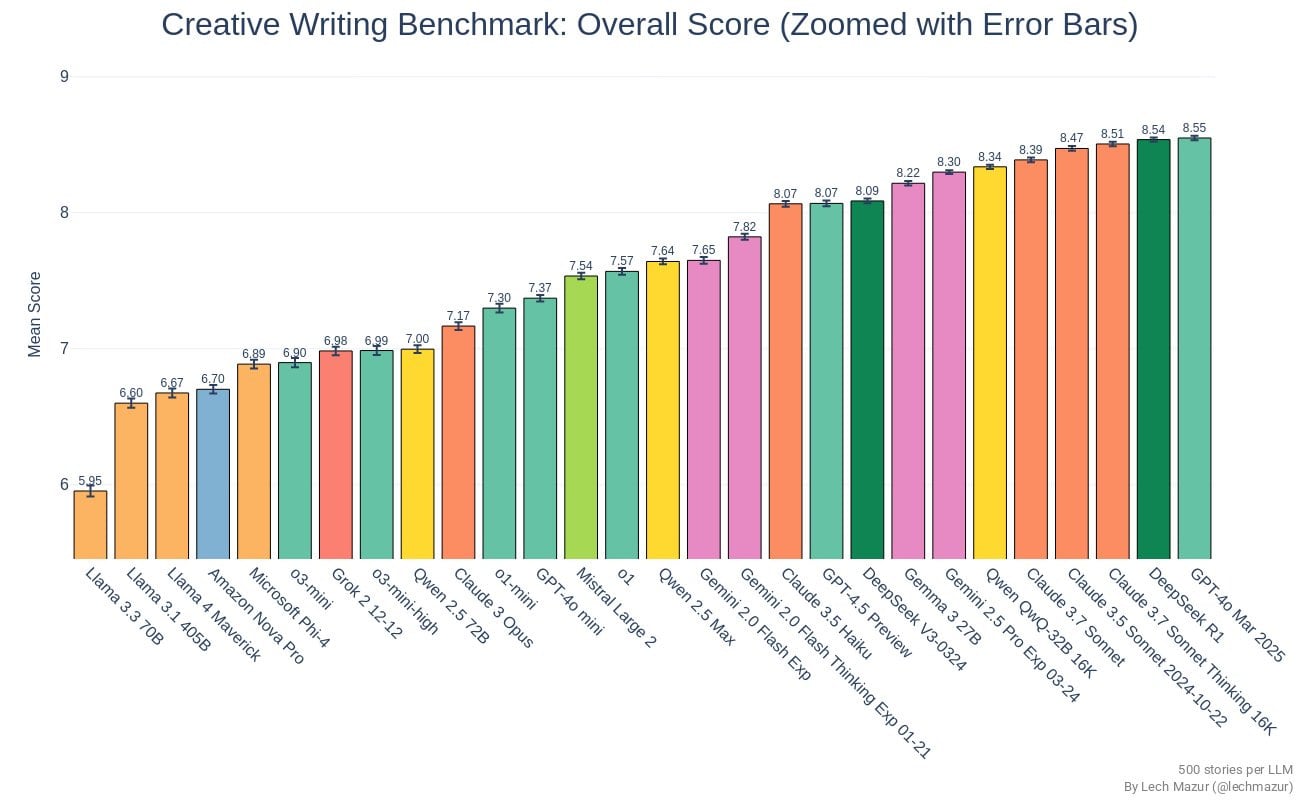
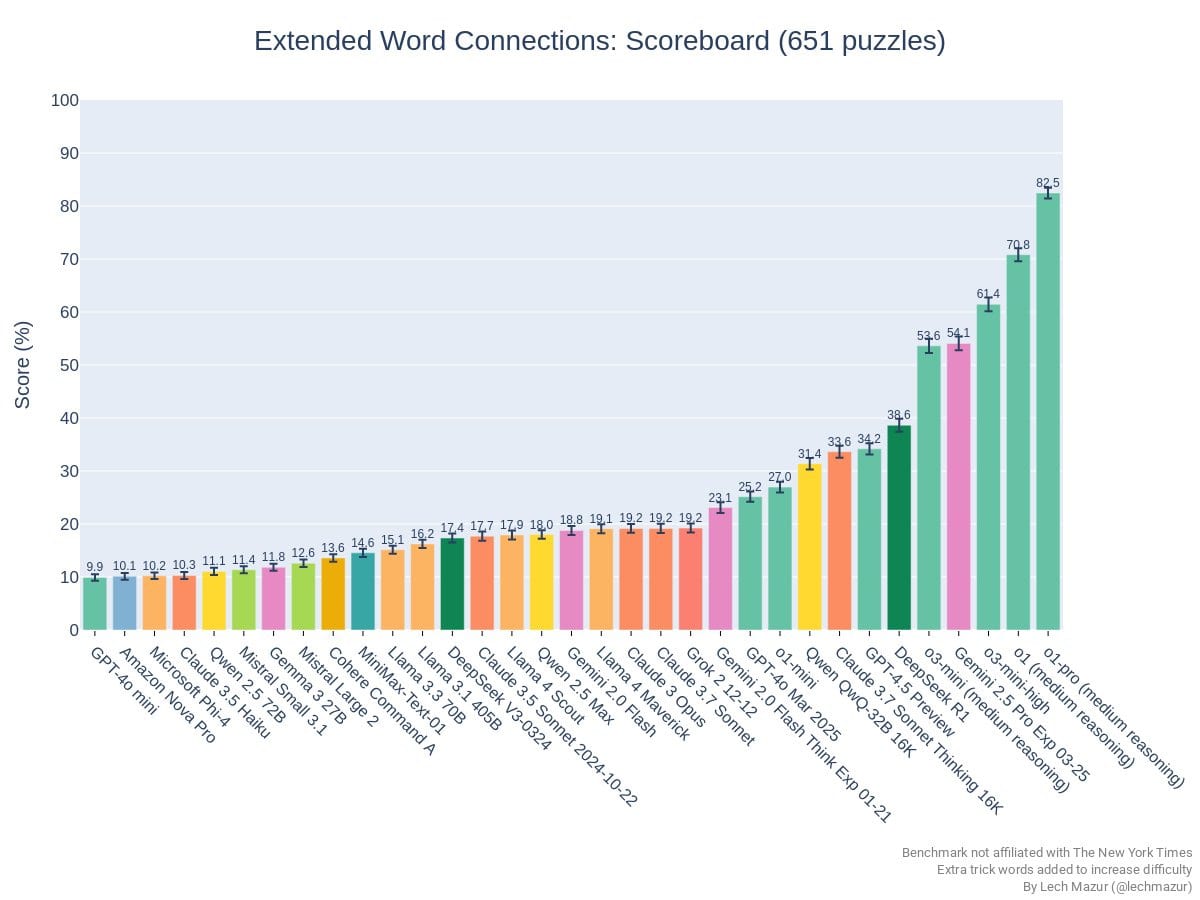
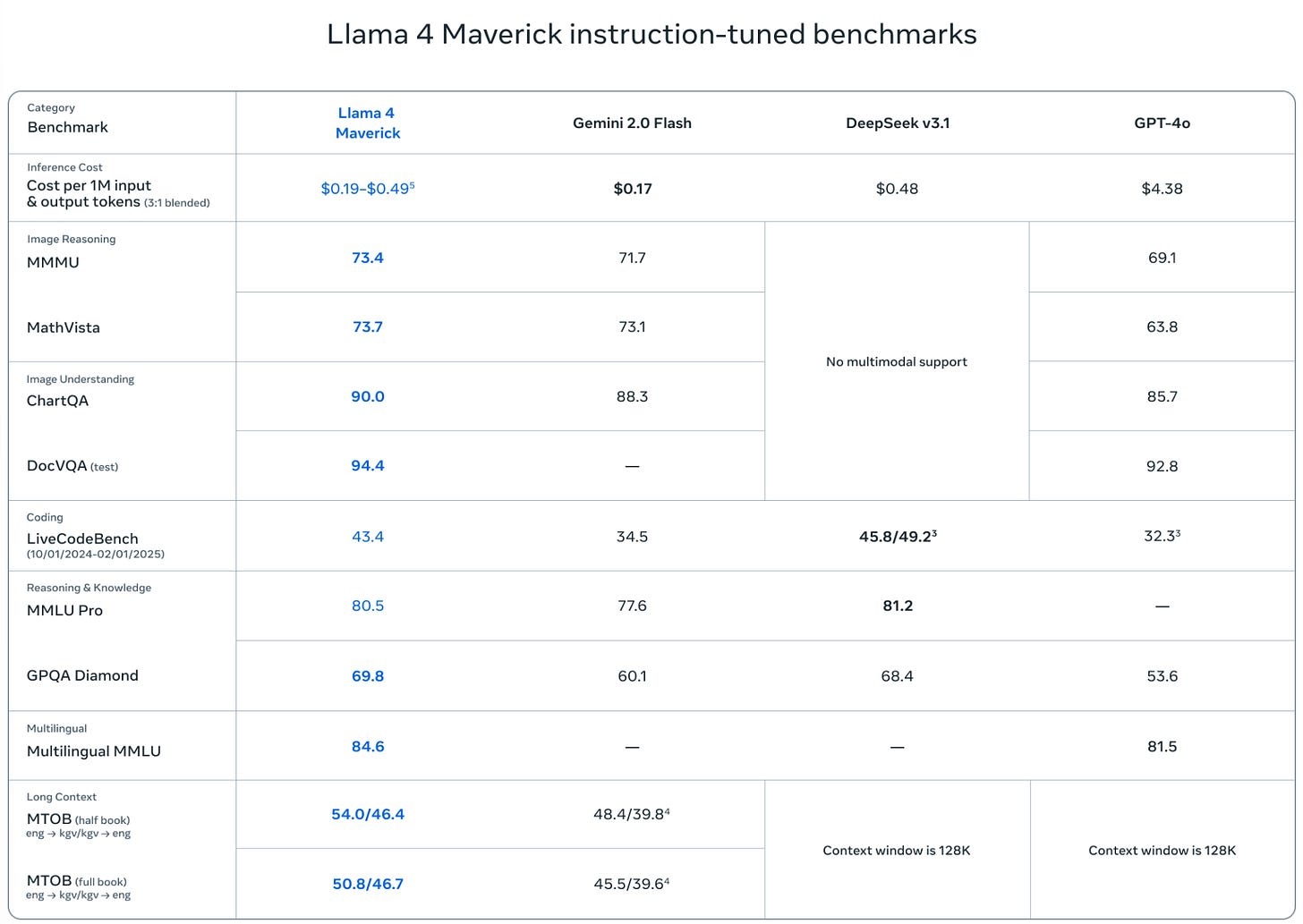
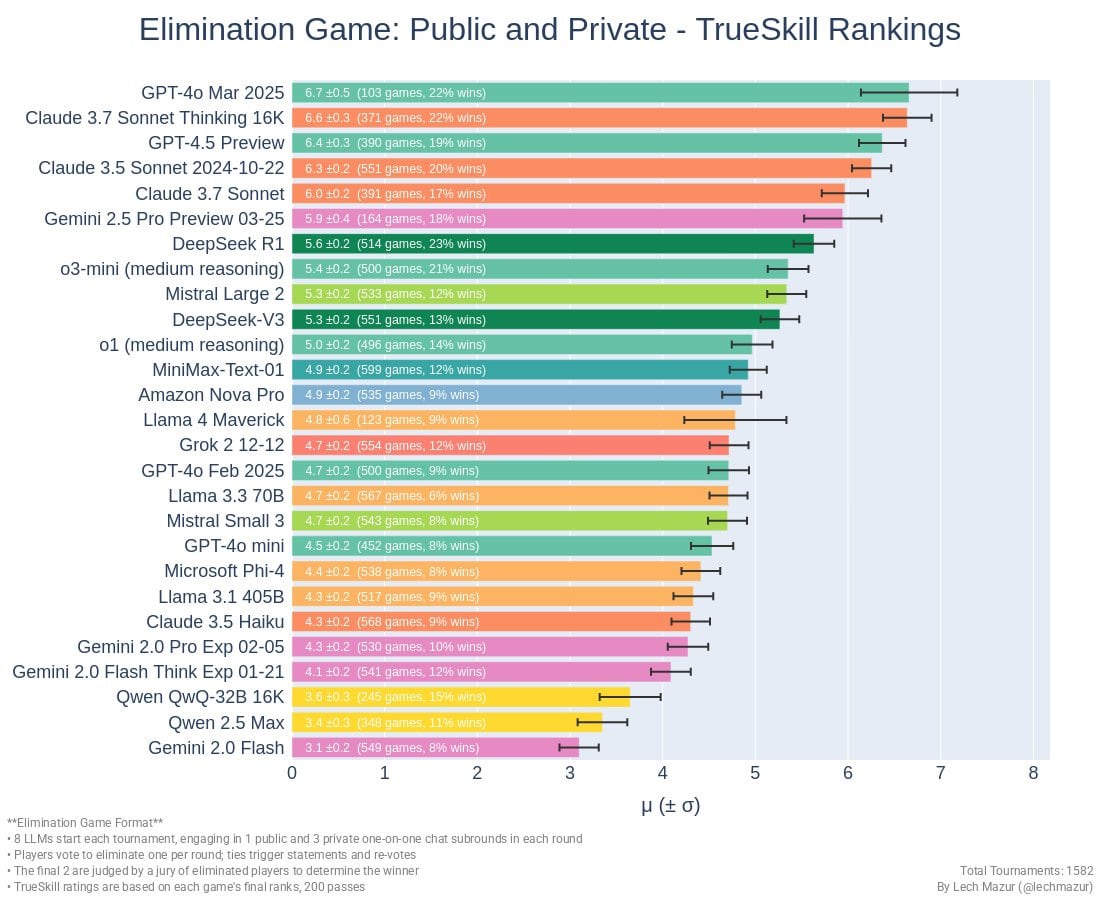
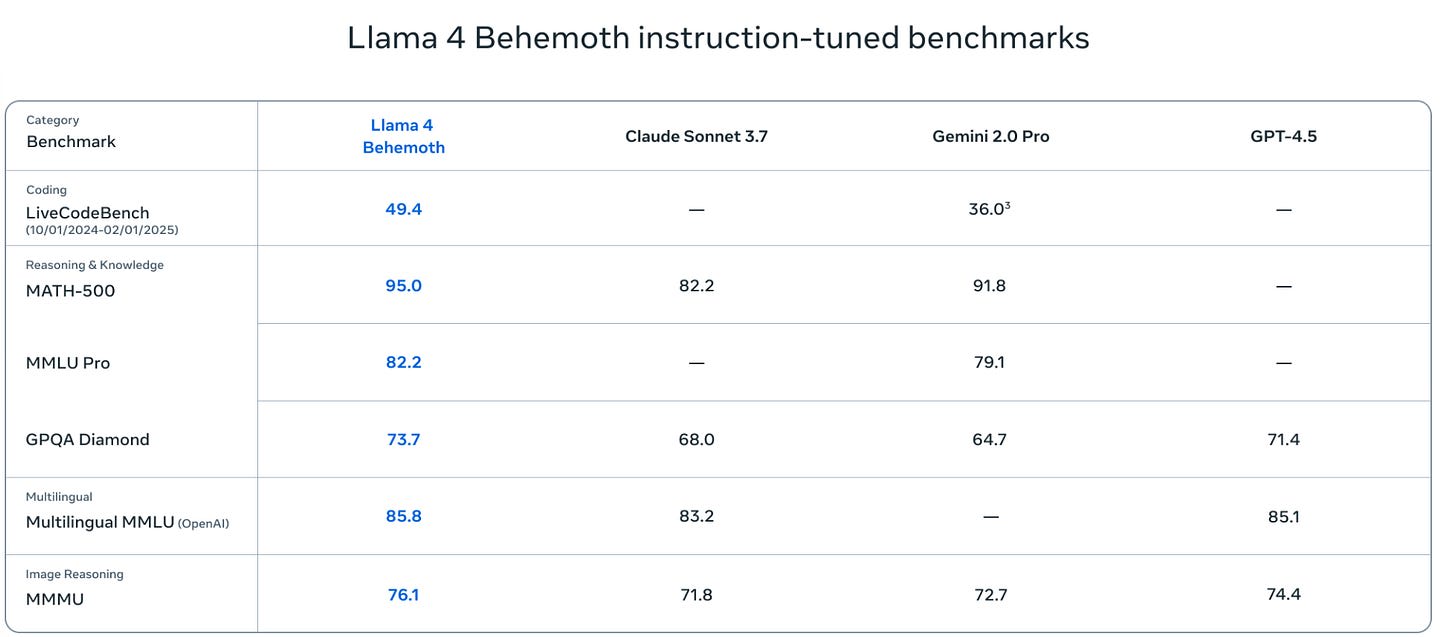
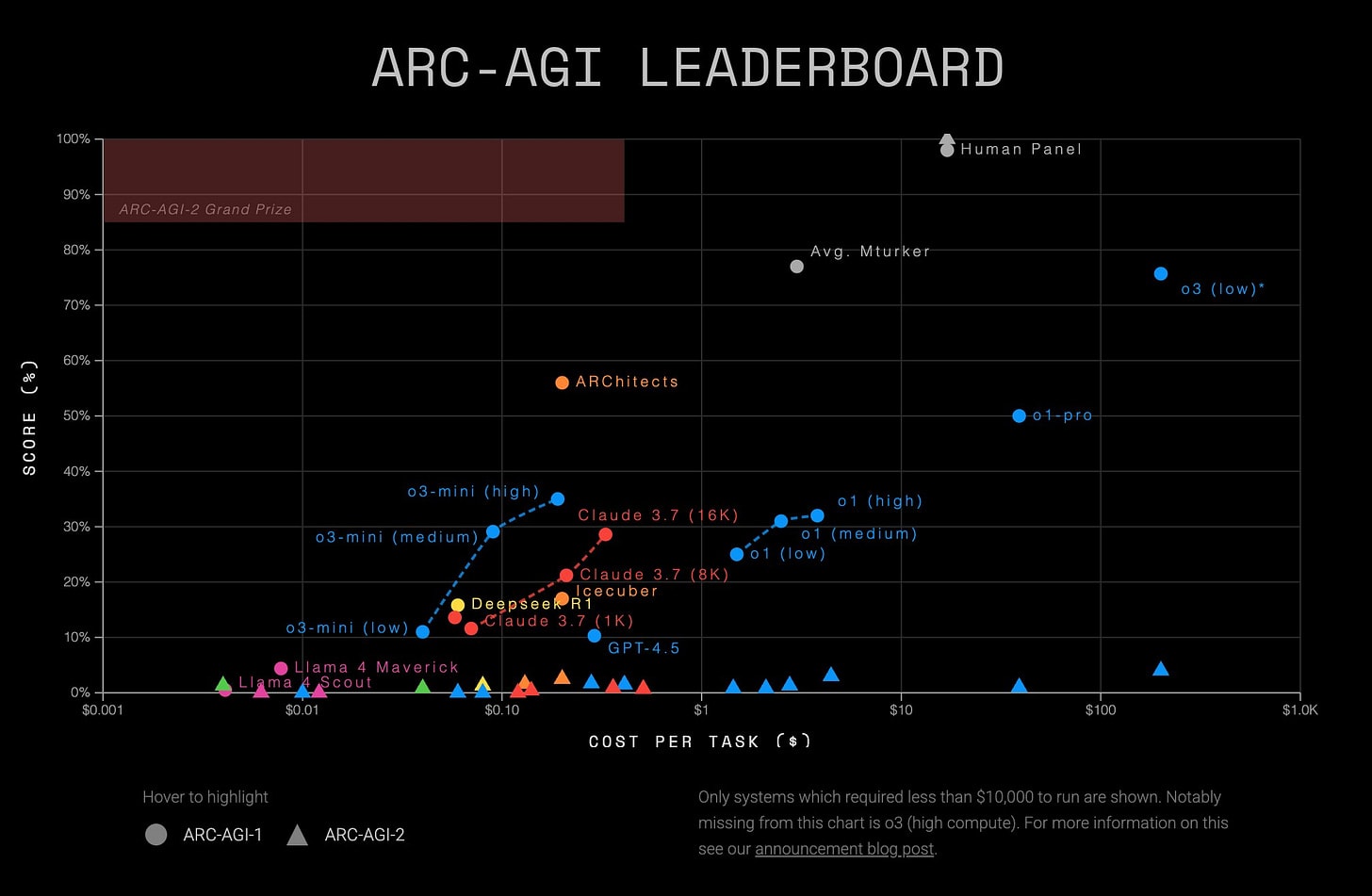
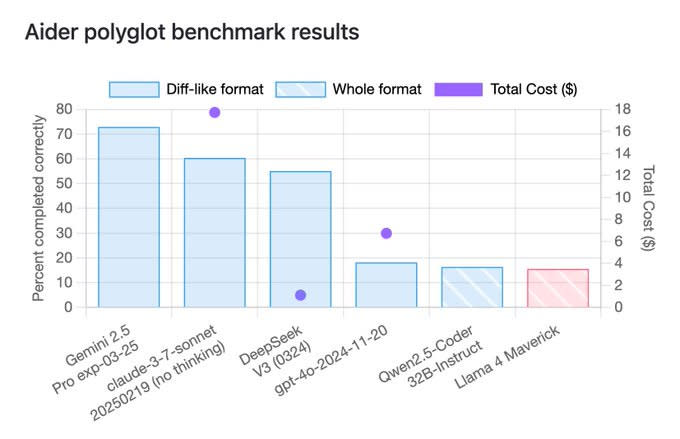
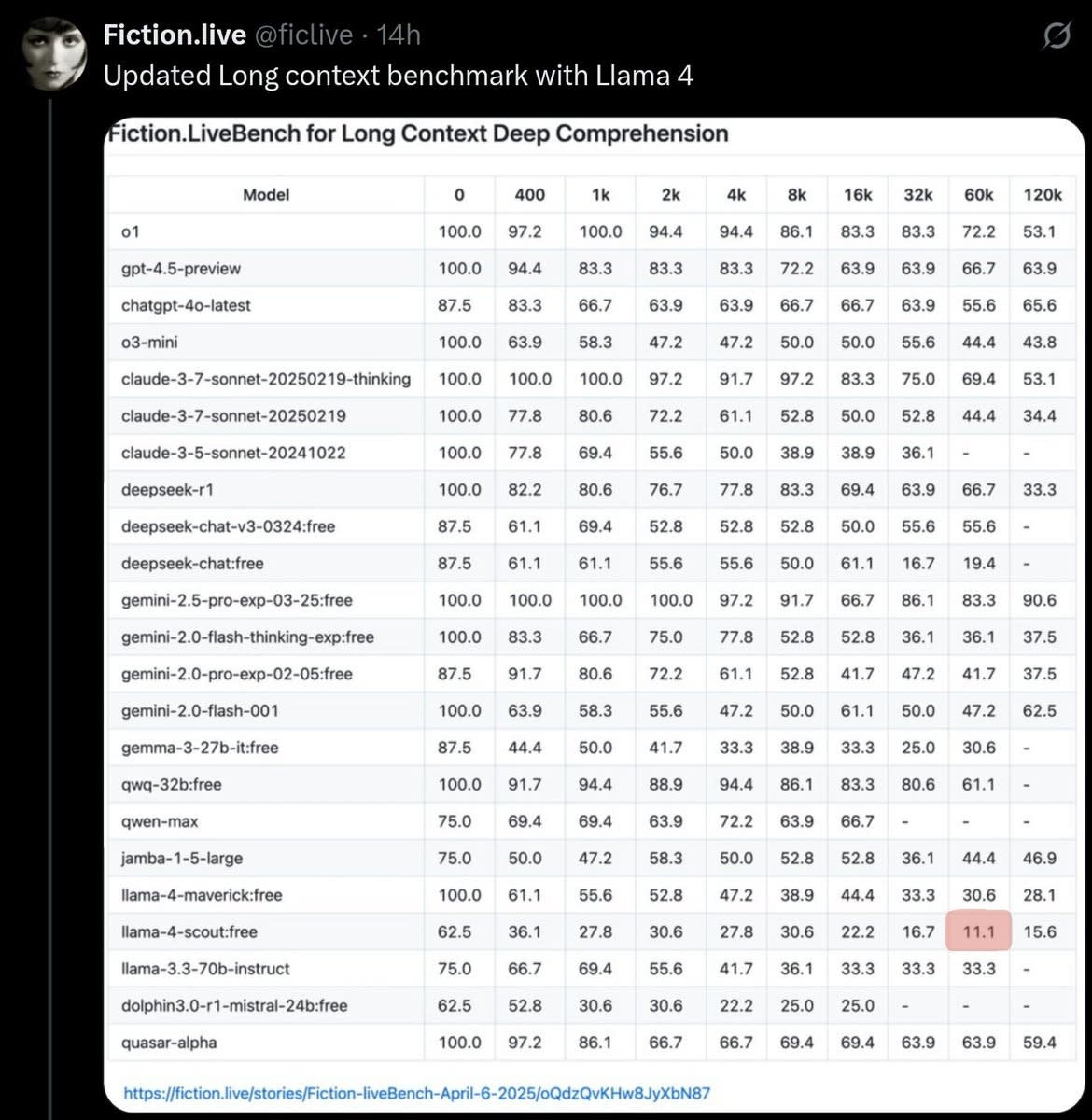
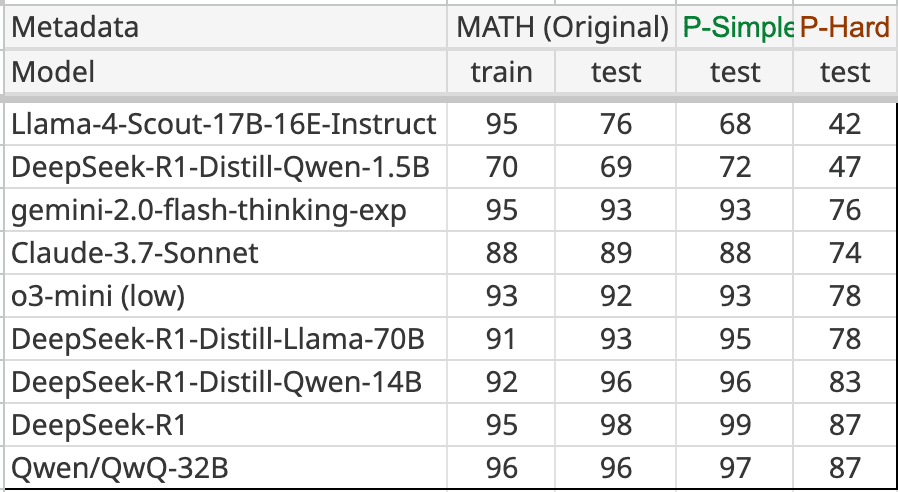
Llama Scout (17B active parameters, 16 experts, 109B total) and Llama Maverick (17B active parameters, 128 experts, 400B total), released on Saturday, look deeply disappointing. They are disappointing on the level of ‘people think they have to be misconfigured to be this bad,’ and people wondering and debating how aggressively the benchmarks were gamed.
This was by far the most negative reaction I have seen to a model release, the opposite of the reaction to Gemini 2.5 Pro. I have seen similarly deeply disappointing and misleading releases, but they were non-American models from labs whose benchmarks and claims we have learned not to take as representing model capabilities.
After this release, I am placing Meta in that category of AI labs whose pronouncements about model capabilities are not to be trusted, that cannot be relied upon to follow industry norms, and which are clearly not on the [...]
---
Outline:
(01:31) Llama We Doing This Again
(03:05) Llama the License Favors Bad Actors
(04:35) Llama You Do It This Way
(09:35) Llama Fight in the Arena
(13:52) Llama Would You Cheat on Other Benchmarks
(19:25) Llama It So Bad on Independent Benchmarks
(27:55) Llama You Don't Like It
(32:30) Llama Should We Care
---
First published:
April 9th, 2025
Source:
https://www.lesswrong.com/posts/FHMcHmW4RKY5JiArJ/llama-does-not-look-good-4-anything
Narrated by TYPE III AUDIO.
---
Images from the article:
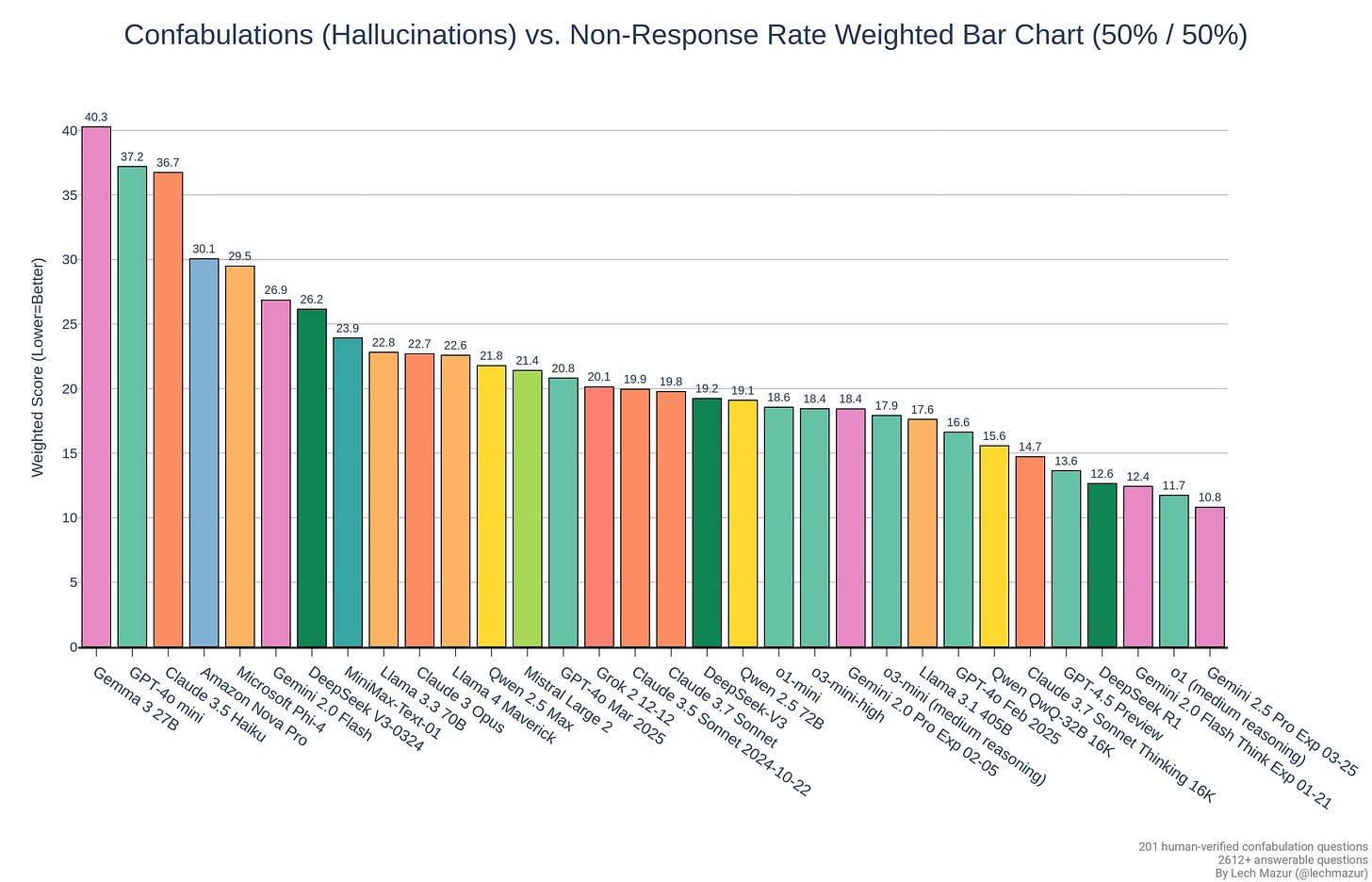
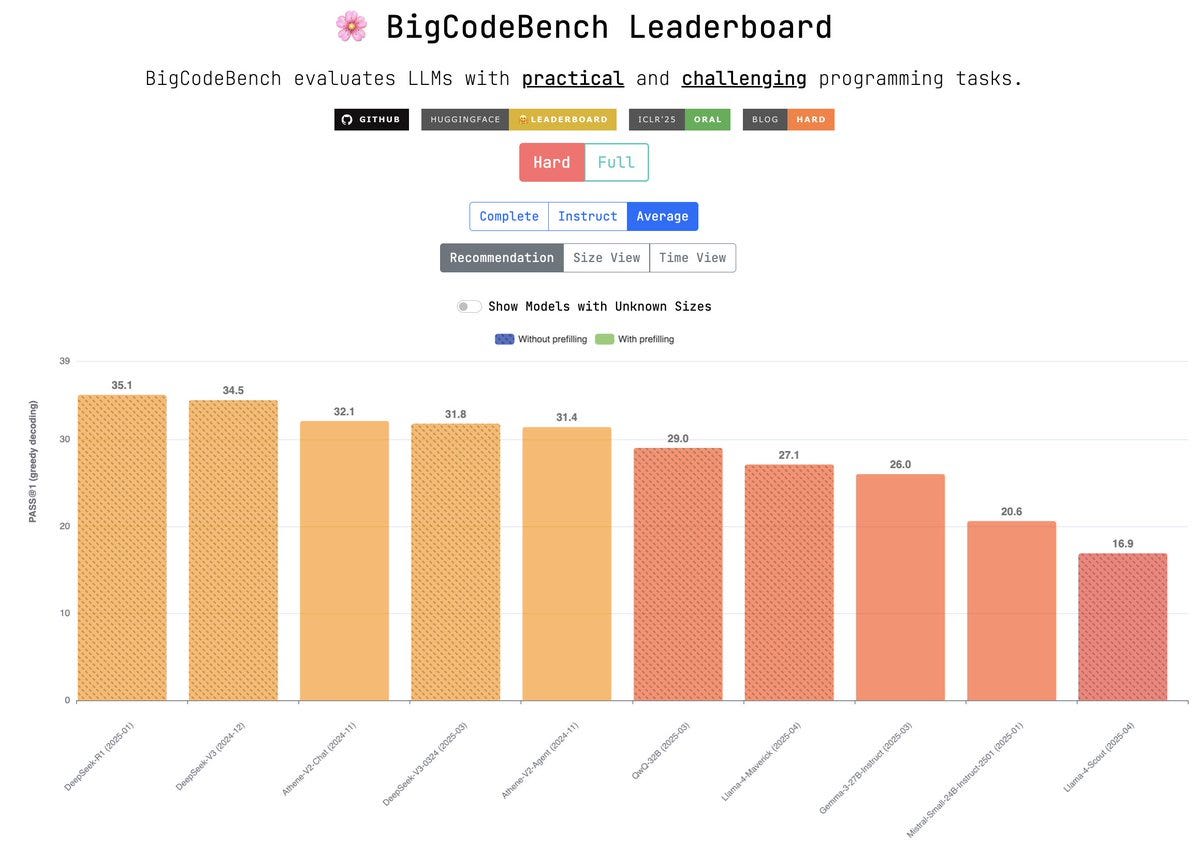
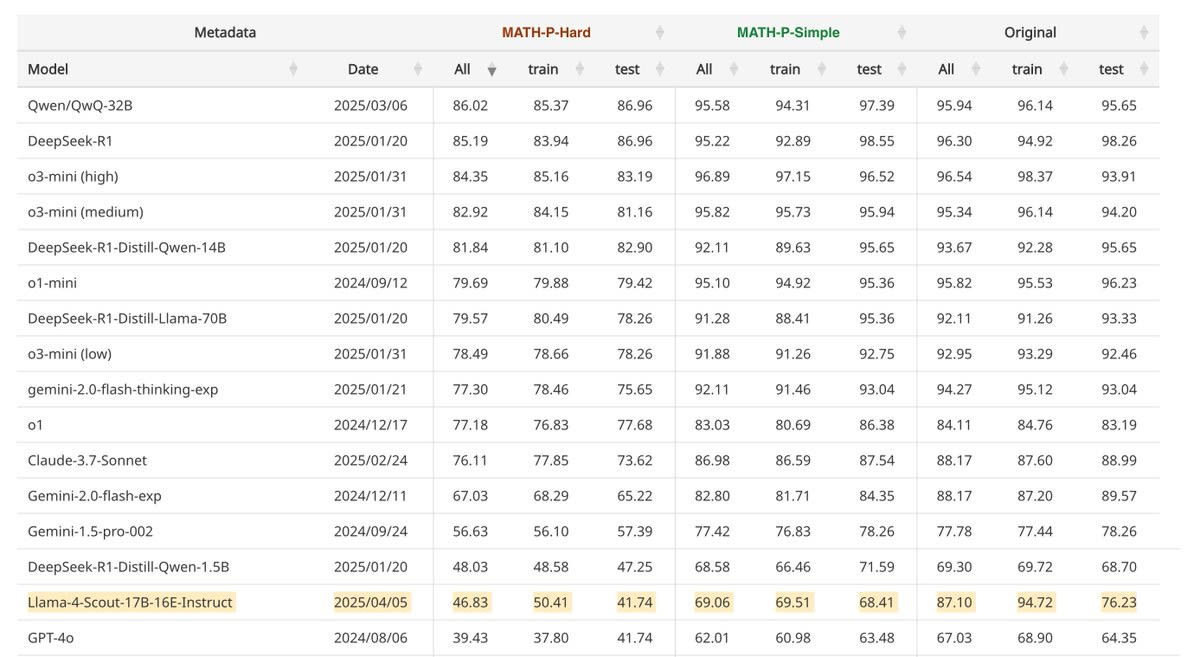

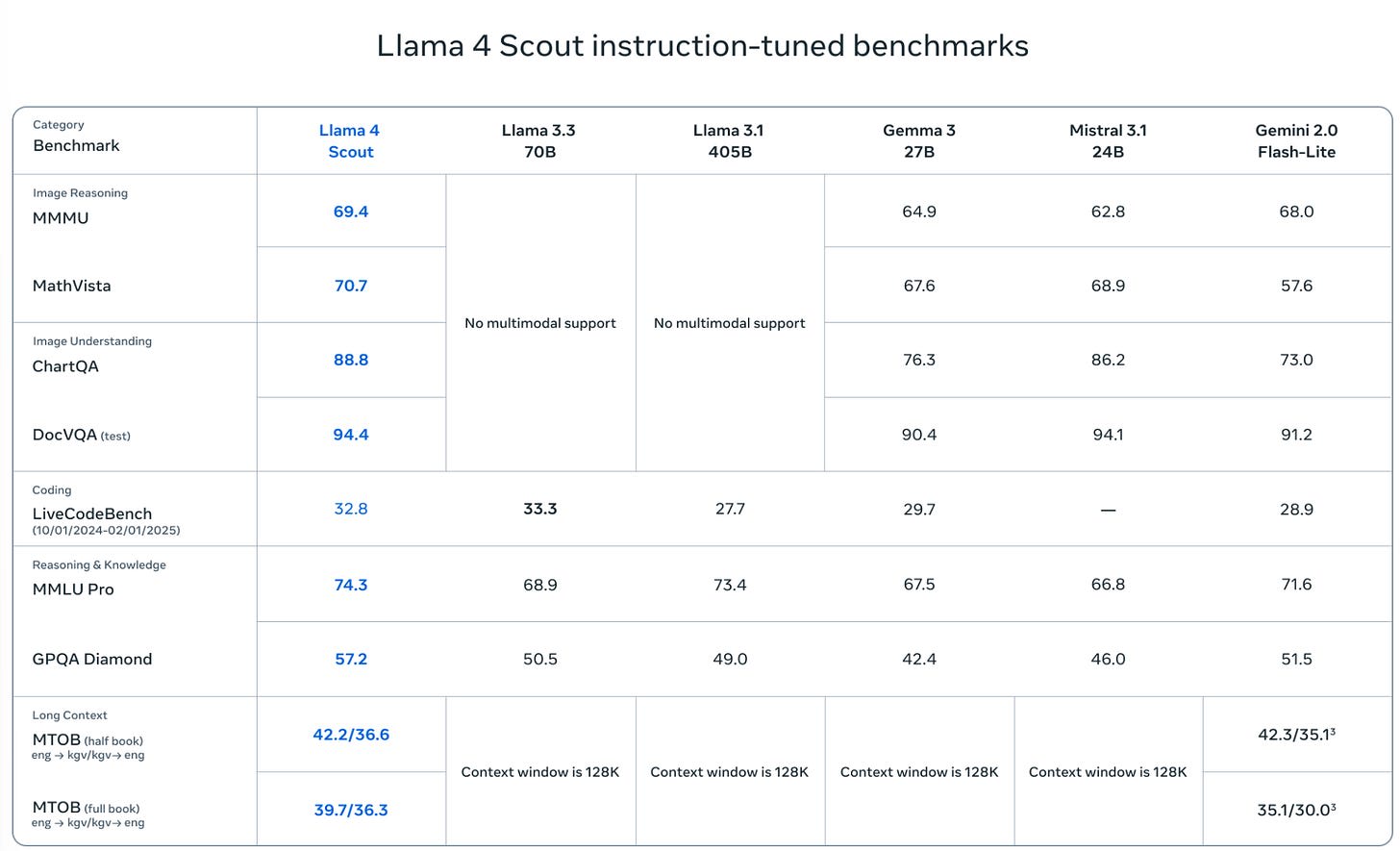


Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00