Bra podcast
Sveriges mest populära poddar

Not too long ago, OpenAI presented a paper on their new strategy of Deliberative Alignment.
The way this works is that they tell the model what its policies are and then have the model think about whether it should comply with a request.
This is an important transition, so this post will go over my perspective on the new strategy.
Note the similarities, and also differences, with Anthropic's Constitutional AI.
How Deliberative Alignment Works
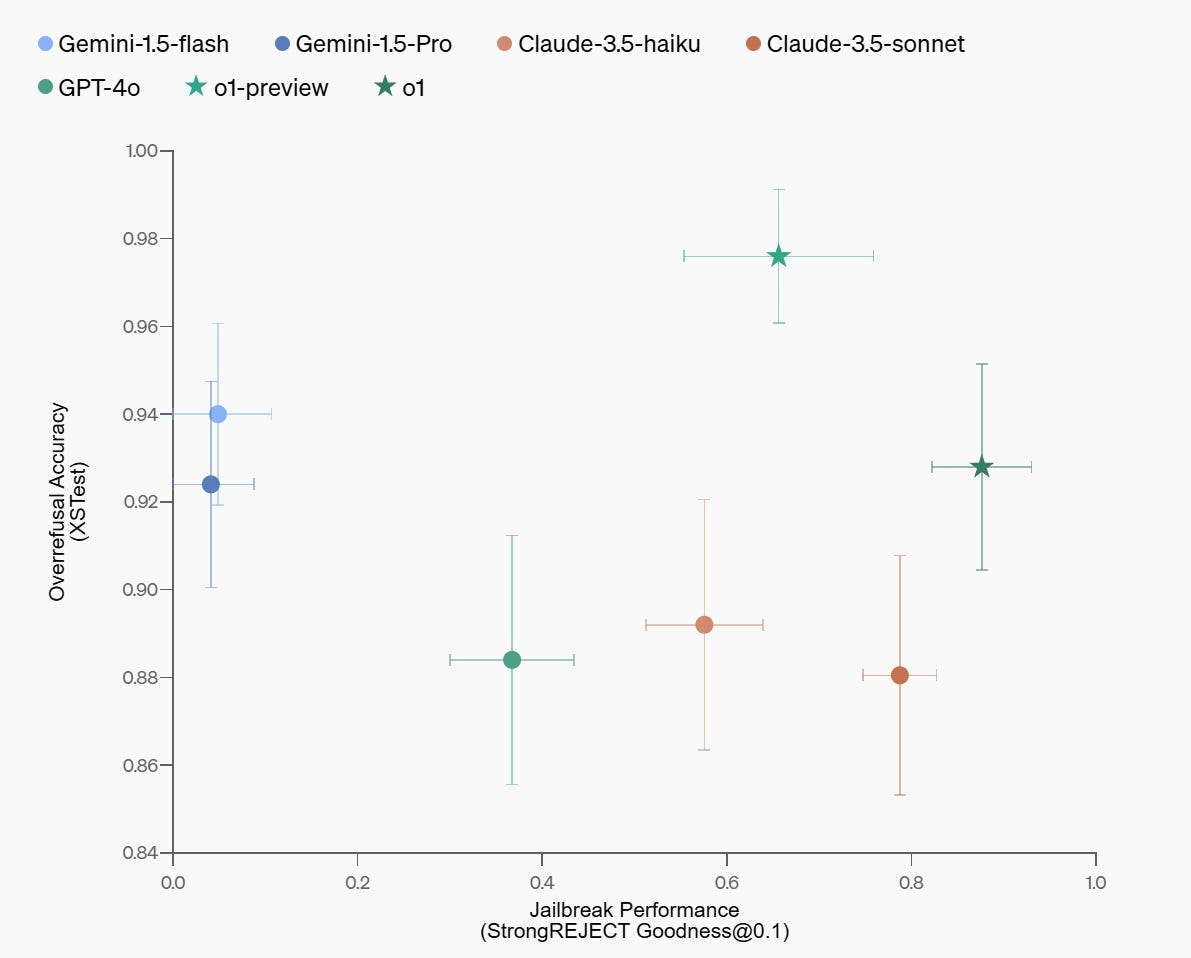
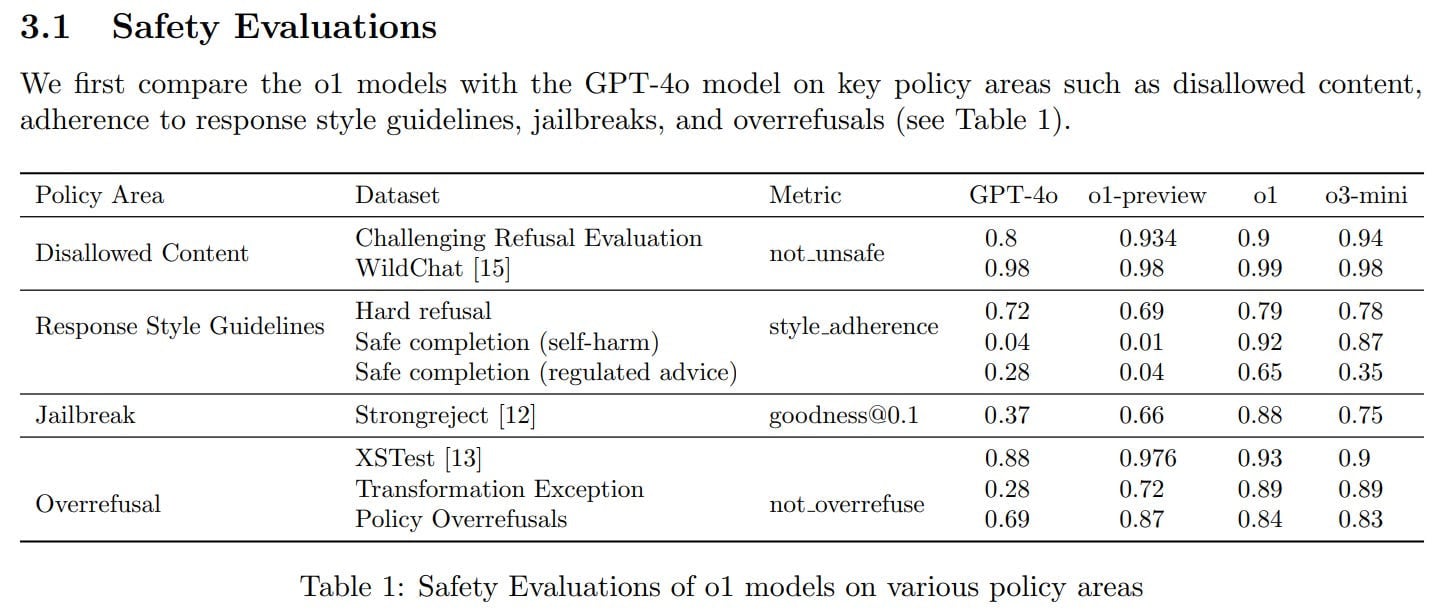
We introduce deliberative alignment, a training paradigm that directly teaches reasoning LLMs the text of human-written and interpretable safety specifications, and trains them to reason explicitly about these specifications before answering.
We used deliberative alignment to align OpenAI's o-series models, enabling them to use chain-of-thought (CoT) reasoning to reflect on user prompts, identify relevant text from OpenAI's internal policies, and draft safer responses.
Our approach achieves highly precise [...]
---
Outline:
(00:29) How Deliberative Alignment Works
(03:27) Why This Worries Me
(07:49) For Mundane Safety It Works Well
The original text contained 3 images which were described by AI.
---
First published:
February 11th, 2025
Source:
https://www.lesswrong.com/posts/CJ4yywLBkdRALc4sT/on-deliberative-alignment
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Kategorier
Förekommer på
00:00
-00:00